前言 了解 驻场研发人员反应生产系统宕机,在开发环境连接线上数据库不会复现。
重启系统后系统正常访问,但是在一周之内又会出现当宕机情况。
在读取项目日志文件之后,发现 OOM:java head space
生产环境项目使用:Spring boot jar 方式部署
Java环境:jdk1.8
第一阶段 主要思路 堆内存溢出,可能是由于某段时间处理内容过多导致的,所以增加堆内存空间解决。
加大堆内存
复现OOM
实时监控
过程 加大堆内存到8G 启动参数上添加
1 java -Xmx8G -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log
这里遇到了一个问题,在紧急响应系统重启后 gc.log 文件会被覆盖,在第二阶段会讲到解决覆盖问题。
Tomcat官方推荐在 setenv.bat/setenv.sh配置,Tomcat 说明
模拟用户访问 使用前端脚本模拟用户操作
实时监控 服务器使用实时监控
方式一:
1 2 3 4 jps -mVl jstat -gc -h10 -t pid 1000 8
方式二:
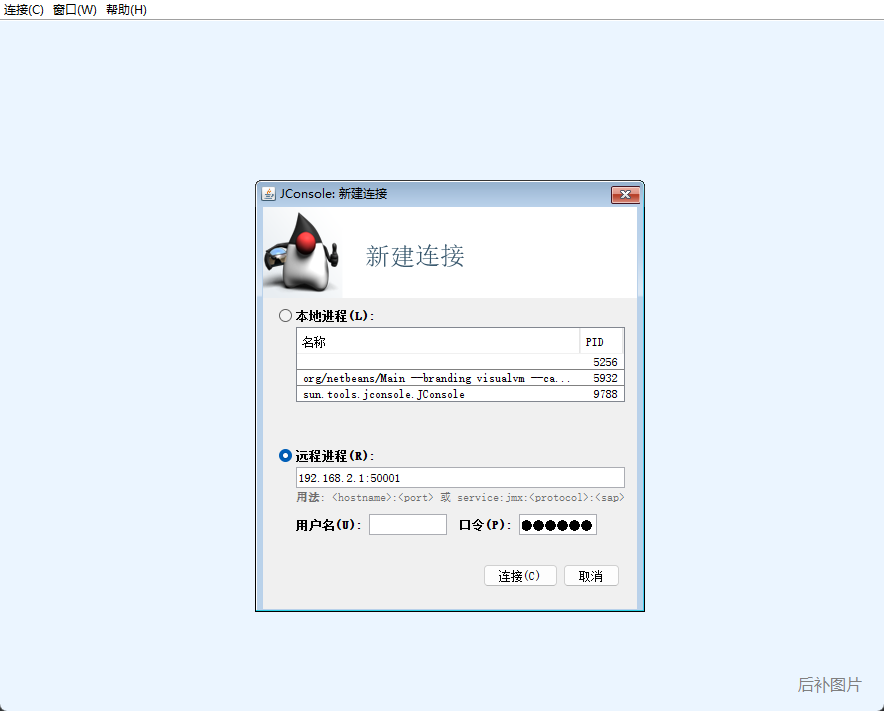
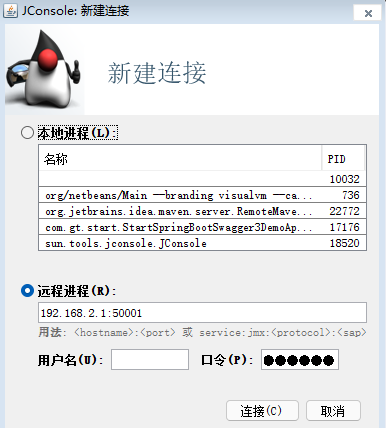
添加程序 jmx启动参数,使用 jconsole实时监控
1 2 3 4 5 6 7 8 java -Djava.rmi.server.hostname=xx.xx.xx.xx -Dfile.encoding=utf-8 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=50001 -Dcom.sun.management.jmxremote.rmi.port=50002 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=maxzhao -jar xxx.jar
使用 jconsole连接
结果 偶发性极强,无法主观复现。
对于线上系统,实时监控效率低下,意义不大。
第二阶段 主要思路 由于实时分析JVM行不通,我们这里在OOM发生时自动导出 dump,然后分析。
打印GC日志、输出oom时的dump文件
分析OOM时的内存dump文件
过程 配置启动参数 打印JVM GC 信息和oom时的dump文件,启动参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 current=`date '+%s'` java \ # 为了更好的复现,最大堆内存改为 4G -Xmx4G \ # 打印出GC详细信息 -XX:+PrintGCDetails \ # 打印时间戳 -XX:+PrintGCDateStamps \ -XX:+PrintHeapAtGC \ # 记录到文件,添加文件名称时间戳,防止紧急重启后覆盖文件 -Xloggc:gc.log-${current} \ # JVM 一个日志文件达到了20M以后,会生成新的,保留50个历史 -XX:+UseGCLogFileRotation \ -XX:GCLogFileSize=20M \ -XX:NumberOfGCLogFiles=50 \ # 内存溢出异常时Dump出当前的堆内存转储快照 -XX:+HeapDumpOnOutOfMemoryError \ -XX:HeapDumpPath=./dump/ \ -jar xxx.jar
这里使用时间戳的方式解决系统重启导致 gc.log 文件被覆盖的问题
这里堆内存设置4G,不能过小,否则可能无法获取真实的OOM产生原因。
查询系统 JVM 参数 查询 Java 进程
查询 vm 参数信息
输出
1 2 3 4 5 6 7 Attaching to process ID 15724, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.291-b10 Non-default VM flags: # 命令行指定的参数 Command line:
实时监控 实时监控分为三块
1、TOP 监控整理进程 现象:内存一直在涨,最总涨到 27% (服务器内存 16G),没有 oom
2、监控 GC 日志 现象:``YGC 正常,Full GC` 正常
OOM分析系统宕机,oom发生 发生在 2022-5-20:17:31
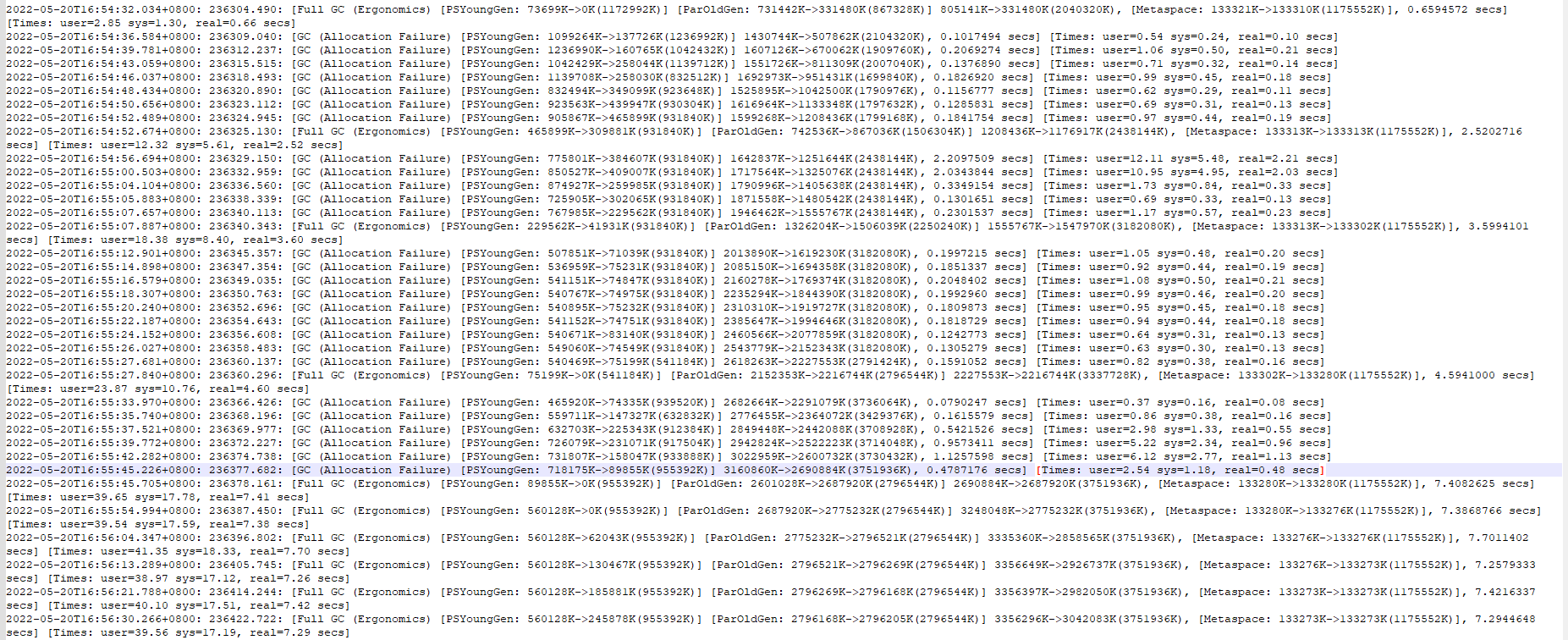
gc.log.xxx日志分析
可以从日志中了解到:
在 oom 前半小时,在 16:54:32开始内存处于不正常的增长, YGC与FGC异常。
FGC频发占用资源。
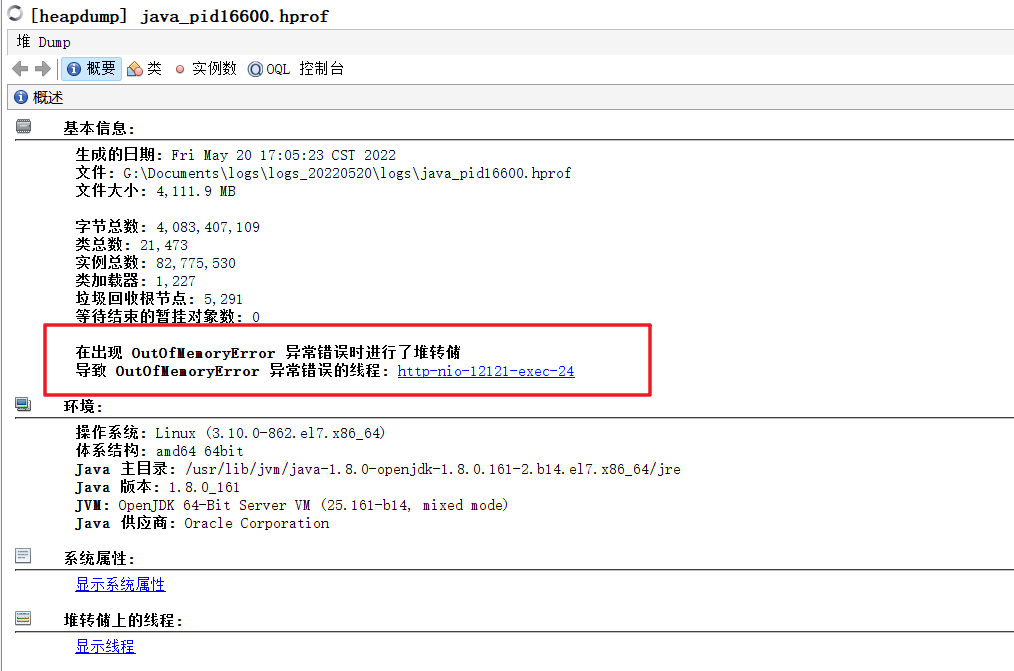
oom dump文件分析dump 文件:java_pid16600.hprof,大小 4.01G(我们配置的最大堆内存4G)。
用 jvisualvm打开 hprof 这里使用 jdk1.8的 jvisualvm
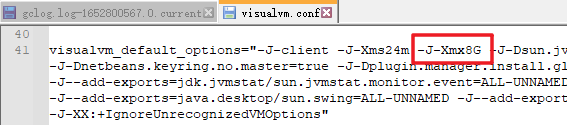
配置 jvisualvm的初始内存配置,本机文件所在路径 ${JAVA_HOME}\lib\visualvm\etc\visualvm.conf
找到 visualvm_default_options 配置 -J-Xmx8G就可以正常打开 4G的hprof。
命令行打开 jvisualvm,点击左上角的文件 -载入
概要信息
在概要信息里,我们可以点击 异常错误的线程 来查看异常信息。
对于OOM来讲,一般情况下,堆栈被几百上千个对象占用,无法判断是否有问题,而且错误的堆栈不一定是产生OOM的原因,可能是压垮整个系统的最后一根稻草,所以具体我们还需要查看堆中的类 和实例
查看类的内容
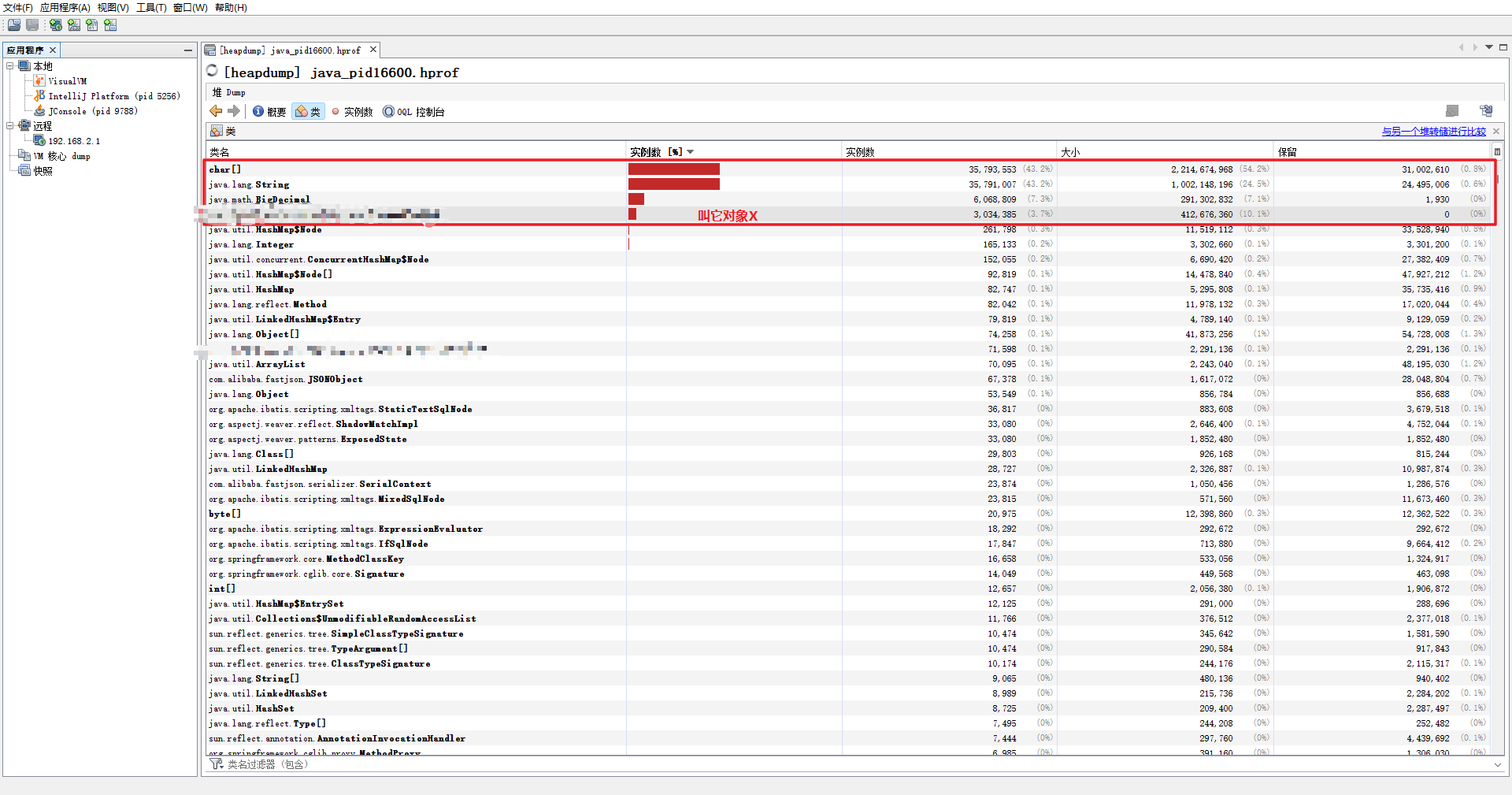
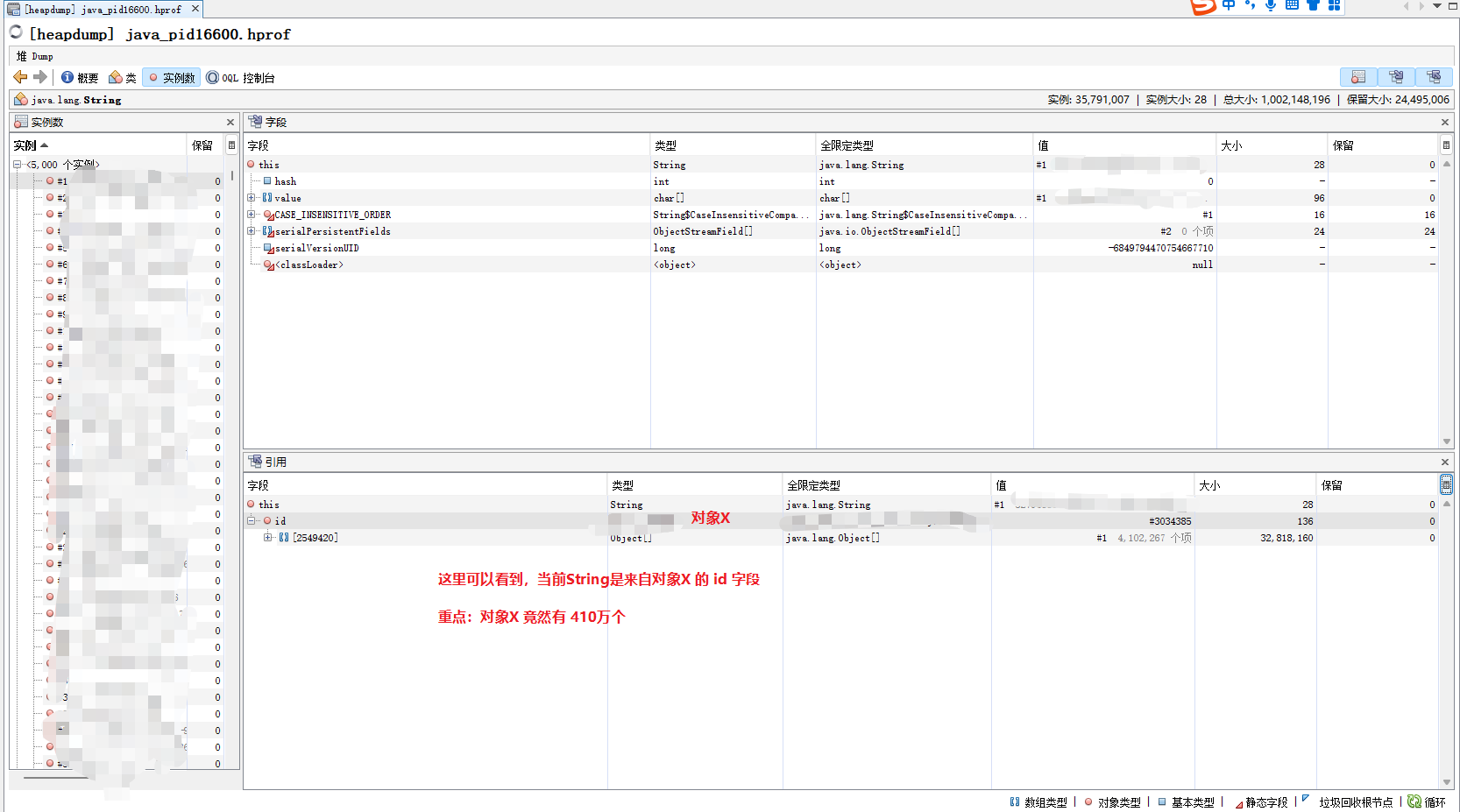
这里我们可以看到
char[] 占用2.2GString 占用 1GBigDecimal 占用 291MB对象X 占用 412MB
查看实例 char[]是比较难看懂的,我们这里直接看 String
双击 String 所在的行
随机看一看其它String 实例,发现绝大部分都是属于 对象X。
而对象X是一个百万级的集合,根据 gc.log.xxx 异常的时间,以及操作日志,找出所有请求的URL。
然后根据这些接口排查持久层返回 对象X 的方法。
相关代码 1 2 3 4 5 6 7 判断条件A是否存在 存在加入where 条件 判断条件B是否存在 存在加入where 条件 判断条件C是否存在 存在加入where 条件 条件D加入where 条件
当前查询没有分页控制,如果主要的三个判断条件都不存在时,查询后会导致结果集过大,从而内存溢出。
修改方式 根据当前业务,这里添加了分页,取第一页 10000条数据,超过10000条则不获取。
特别注意
程序中不应该出现没有分页的情况,如果出现,请考虑数据量。
后端程序不能依赖前端参数来控制代码逻辑,要使得程序可控,提高代码的健壮性。
程序一定要有完整的操作日志(包括但不限于接口、方法的参数、响应数据)
Spring Booot jar内置 Tomcat core,可以不用Tomcat部署。JVM堆内存不建议设置过大,默认为服务器 1/4
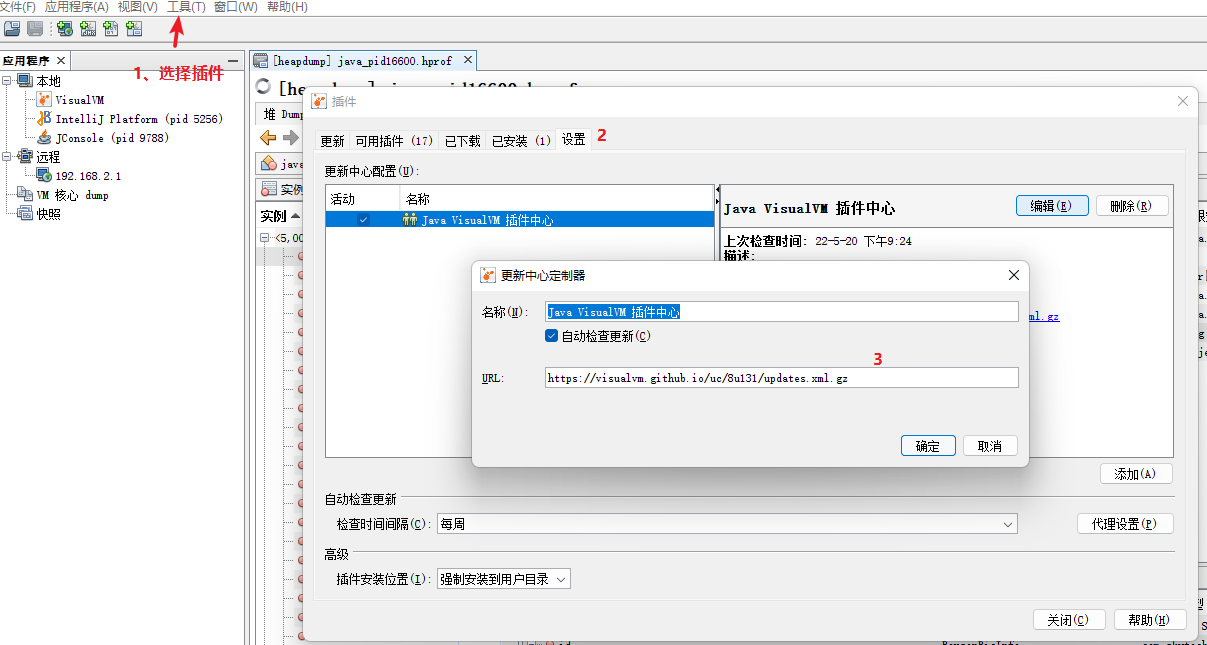
附 安装 VisualGC 插件 当前插件可以用于实时监控
填入地址:https://visualvm.github.io/uc/8u131/updates.xml.gz
插件官网:https://visualvm.github.io/plugins.html
本文地址: https://github.com/maxzhao-it/blog/post/a9539589/