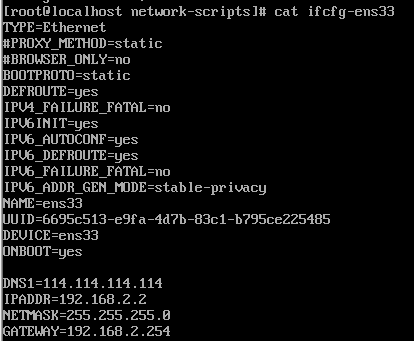
tar -zxvf elasticsearch-7.14.0-linux-x86_64.tar.gz mv elasticsearch-7.14.0 /opt/elasticsearch-7.14.0 tar -zxvf kibana-7.14.0-linux-x86_64.tar.gz mv kibana-7.14.0-linux-x86_64 /opt/kibana-7.14.0
添加用户
1 2 3 4 5 6 7 8 9 10 11
# 添加账号 useradd es # 修改密码 passwd es # 把用户加入到 root 组 usermod -aG root es # 加入到 sudo 中 sudo vim /etc/sudoers # 添加一行: es ALL=(ALL) ALL su es sudo chown es ./
新 Centos 系统配置
max file
修改
1
sudo vim /etc/security/limits.conf
添加
1 2 3 4
* soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536
# 端口 server.port:5601 # 本机IP server.host:"192.168.2.2" #代理下指定一个路径挂载Kibana。 #使用服务器。rewriteBasePath的设置告诉Kibana是否应该删除basePath #此设置不能以斜杠结束。 #server.basePath: "" # 重写前缀为 server.basePath,默认为true. #server.rewriteBasePath: false # Specifies the public URL at which Kibana is available for end users. If # `server.basePath` is configured this URL should end with the same basePath. #server.publicBaseUrl: "" # 请求最大负载大小 #server.maxPayload: 1048576 # 服务名称 #server.name: "your-hostname" # Elasticsearch instances. elasticsearch.hosts: ["http://192.168.2.2:9200"]
# Optional settings that provide the paths to the PEM-format SSL certificate and key files. # These files are used to verify the identity of Kibana to Elasticsearch and are required when # xpack.security.http.ssl.client_authentication in Elasticsearch is set to required. #elasticsearch.ssl.certificate: /path/to/your/client.crt #elasticsearch.ssl.key: /path/to/your/client.key
# Optional setting that enables you to specify a path to the PEM file for the certificate # authority for your Elasticsearch instance. #elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ] # To disregard the validity of SSL certificates, change this setting's value to 'none'. #elasticsearch.ssl.verificationMode: full
# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of # the elasticsearch.requestTimeout setting. #elasticsearch.pingTimeout: 1500
# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value # must be a positive integer. #elasticsearch.requestTimeout: 30000
# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 30000 # List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 30000
# Logs queries sent to Elasticsearch. Requires logging.verbose set to true. #elasticsearch.logQueries: false
# Specifies the path where Kibana creates the process ID file. #pid.file: /run/kibana/kibana.pid
# Enables you to specify a file where Kibana stores log output. #logging.dest: stdout
# Set the value of this setting to true to suppress all logging output. #logging.silent: false
# Set the value of this setting to true to suppress all logging output other than error messages. #logging.quiet: false
# Set the value of this setting to true to log all events, including system usage information # and all requests. #logging.verbose: false
# Set the interval in milliseconds to sample system and process performance # metrics. Minimum is 100ms. Defaults to 5000. #ops.interval: 5000
# Specifies locale to be used for all localizable strings, dates and number formats. # Supported languages are the following: English - en , by default , Chinese - zh-CN . #i18n.locale: "en"
cd ~/ wget https://artifacts.elastic.co/downloads/logstash/logstash-8.4.1-linux-x86_64.tar.gz tar -zxf logstash-8.4.1-linux-x86_64.tar.gz mv logstash-8.4.1 logstash
match => { "field1" => "value1" "field2" => "value2" ... } # or as a single line. No commas between entries: match => { "field1" => "value1""field2" => "value2" }
如果是这种需求就用到了 grok 插件,该插件是 Logstash 将普通文本解析成结构化数据的最好的方式。(这可不是我非要安利,是官网上说的:Grok is currently the best way in logstash to parse crappy unstructured log data into something structured and queryable.)
# 添加账号 useradd es # 修改密码 passwd es # 把用户加入到 root 组 usermod -aG es root sudo yum install -y wget # 加入到 sudo 中 sudo vim /etc/sudoers # 添加一行: es ALL=(ALL) ALL su es sudo chown es ./
新 Centos 系统配置
max file
修改
1
sudo vim /etc/security/limits.conf
添加
1 2 3 4
* soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536
cd /home/es/ mkdir tools && cd tools wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.0-linux-x86_64.tar.gz wget -b https://artifacts.elastic.co/downloads/kibana/kibana-8.6.0-linux-x86_64.tar.gz wget -b https://artifacts.elastic.co/downloads/logstash/logstash-8.6.0-linux-x86_64.tar.gz
解压
1 2 3 4 5
cd /home/es/ tar -zxf /home/es/tools/elasticsearch-8.6.0-linux-x86_64.tar.gz -C /home/es/ tar -zxf /home/es/tools/kibana-8.6.0-linux-x86_64.tar.gz -C /home/es/ mv /home/es/elasticsearch-8.6.0 /home/es/elasticsearch mv /home/es/kibana-8.6.0 /home/es/kibana
核心配置
ElasticSearch
配置证书
1 2 3 4 5 6 7 8
/home/es/elasticsearch/bin/elasticsearch-certutil ca #Please enter the desired output file [elastic-stack-ca.p12]: 输入名称 #Enter password for elastic-stack-ca.p12 : 输入密码 /home/es/elasticsearch/bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12 #Enter password for CA (elastic-stack-ca.p12) : 输入上面的密码 #Please enter the desired output file [elastic-certificates.p12]: 输入当前节点的名称 #Enter password for elastic-certificates.p12 : 输入当前节点的密码 mv /home/es/elasticsearch/elastic-certificates.p12 /home/es/elasticsearch/config/
[root@localhost bin]# ./elasticsearch-certutil ca --pem future versions of Elasticsearch will require Java 11; your Java version from [/opt/module/haoke/jdk1.8.0_141/jre] does not meet this requirement This tool assists you in the generation of X.509 certificates and certificate signing requests for use with SSL/TLSin the Elastic stack.
The 'ca' mode generates a new 'certificate authority' This will create a new X.509 certificate and private key that can be used to sign certificate when running in'cert' mode.
Use the 'ca-dn' option if you wish to configure the 'distinguished name' of the certificate authority
By default the 'ca' mode produces a single PKCS#12 output file which holds: * The CA certificate * The CA's private key If you elect to generate PEM format certificates (the -pem option), then the output will be a zip file containing individual files for the CA certificate and private key Please enter the desired output file [elastic-stack-ca.zip]:
[root@localhost bin]# ./elasticsearch-setup-passwords interactive future versions of Elasticsearch will require Java 11; your Java version from [/opt/module/haoke/jdk1.8.0_141/jre] does not meet this requirement Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user. You will be prompted to enter passwords as the process progresses. Please confirm that you would like to continue [y/N]y
Enter password for [elastic]: Reenter password for [elastic]: Enter password for [apm_system]: Reenter password for [apm_system]: Enter password for [kibana]: Reenter password for [kibana]: Enter password for [logstash_system]: Reenter password for [logstash_system]: Enter password for [beats_system]: Reenter password for [beats_system]: Enter password for [remote_monitoring_user]: Reenter password for [remote_monitoring_user]: Changed password for user [apm_system] Changed password for user [kibana] Changed password for user [logstash_system] Changed password for user [beats_system] Changed password for user [remote_monitoring_user] Changed password for user [elastic]
问题:
max file descriptors [4096] for elasticsearch process is too low
修改
1
sudo vim /etc/security/limits.conf
添加
1 2 3 4
* soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536
执行
1
sudo source /etc/security/limits.conf
max ``virtualmemory areas vm.max_map_count [65530] ``istoo low, increase to at least [262144]
# 端口 server.port:5601 # 本机IP server.host:"192.168.2.2" #代理下指定一个路径挂载Kibana。 #使用服务器。rewriteBasePath的设置告诉Kibana是否应该删除basePath #此设置不能以斜杠结束。 #server.basePath: "" # 重写前缀为 server.basePath,默认为true. #server.rewriteBasePath: false # Specifies the public URL at which Kibana is available for end users. If # `server.basePath` is configured this URL should end with the same basePath. #server.publicBaseUrl: "" # 请求最大负载大小 #server.maxPayload: 1048576 # 服务名称 #server.name: "your-hostname" # Elasticsearch instances. elasticsearch.hosts: ["http://192.168.2.2:9200"]
# Optional settings that provide the paths to the PEM-format SSL certificate and key files. # These files are used to verify the identity of Kibana to Elasticsearch and are required when # xpack.security.http.ssl.client_authentication in Elasticsearch is set to required. #elasticsearch.ssl.certificate: /path/to/your/client.crt #elasticsearch.ssl.key: /path/to/your/client.key
# Optional setting that enables you to specify a path to the PEM file for the certificate # authority for your Elasticsearch instance. #elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ] # To disregard the validity of SSL certificates, change this setting's value to 'none'. #elasticsearch.ssl.verificationMode: full
# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of # the elasticsearch.requestTimeout setting. #elasticsearch.pingTimeout: 1500
# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value # must be a positive integer. #elasticsearch.requestTimeout: 30000
# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 30000 # List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 30000
# Logs queries sent to Elasticsearch. Requires logging.verbose set to true. #elasticsearch.logQueries: false
# Specifies the path where Kibana creates the process ID file. #pid.file: /run/kibana/kibana.pid
# Enables you to specify a file where Kibana stores log output. #logging.dest: stdout
# Set the value of this setting to true to suppress all logging output. #logging.silent: false
# Set the value of this setting to true to suppress all logging output other than error messages. #logging.quiet: false
# Set the value of this setting to true to log all events, including system usage information # and all requests. #logging.verbose: false
# Set the interval in milliseconds to sample system and process performance # metrics. Minimum is 100ms. Defaults to 5000. #ops.interval: 5000
# Specifies locale to be used for all localizable strings, dates and number formats. # Supported languages are the following: English - en , by default , Chinese - zh-CN . #i18n.locale: "en"
yum -y install openssl-devel gcc gcc-c++ tar -xvf keepalived-2.2.2.tar.gz cd keepalived-2.2.2 ./configure --prefix=/usr/local/keepalived make && make install mkdir /etc/keepalived
安装后的目录
1 2
yum install tree -y tree -l /usr/local/keepalived/etc
# CentOS-Base.repo # # The mirror system uses the connecting IP address of the client and the # update status of each mirror to pick mirrors that are updated to and # geographically close to the client. You should use this for CentOS updates # unless you are manually picking other mirrors. # # If the mirrorlist= does not work for you, as a fall back you can try the # remarked out baseurl= line instead. # #
[base] name=CentOS-$releasever - Base baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/os/$basearch/ #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-7 #released updates [updates] name=CentOS-$releasever - Updates baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/updates/$basearch/ #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-7 #additional packages that may be useful [extras] name=CentOS-$releasever - Extras baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/extras/$basearch/ #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-7 #additional packages that extend functionality of existing packages [centosplus] name=CentOS-$releasever - Plus baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/centosplus/$basearch/ #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus gpgcheck=1 enabled=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-7