POI设置单元格下拉列表(级联列表、自动填充)
- 单独下拉列表
- 级联列表
- 自动填充
1 | import org.apache.poi.hssf.usermodel.DVConstraint; |
1 | import org.apache.poi.hssf.usermodel.DVConstraint; |
pacman升级时,有不少软件不需要升级或是升级后不稳定,可以用下面方式忽略升级
/etc/pacman.conf 中查找 #IgnorePkg =
后面添加不想升级的软件包
IgnorePkg 软件包名称IgnoreGroup 软件包组名称1 | pacman -Sy abc #和源同步后安装名为abc的包 |
Docker安装可以参考:
docker 节点1 | docker pull centos |
这里如果没有权限,则参考 Manjaro安装Docker 中的分组操作。
1 | docker images |
greenplum的节点1 | # 用 exit退出 |
注意:
exit退出后,容器停止(Exited)命令解释:为
centos这个镜像创建一个容器
run: 在新的容器中运行命令 .run=create+start-it:-i和-t, 为该docker创建一个伪终端,这样就可以进入到容器的交互模式--namegp-master容器名称centos: 镜像*/bin/bash:表示启动容器后启动bash。docker中必须要保持一个进程的运行,要不然整个容器启动后就会马上kill itself查看帮助:
docker run --help守护态运行,通过
run后加-d实现
进入每个greenplum节点,配置基础环境
由于docker的centos镜像是centos的简化版本,里面有很多包是没有安装的,会影响到后面部署greenplum,因此在docker的每个节点中安装相关的依赖包
1 | # 查看正在运行的容器 |
1 | yum install -y net-tools which openssh-clients openssh-server less zip unzip iproute |
docker中默认没有启动ssh,为了方便各节点之间的互连,创建相关的认证key,并启动docker的每个节点里面的ssh
1 | ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key |
在每个docker节点中添加如下配置,方便后续greenplum集群的配置文件中用到,ip为各个docker节点中的ip地址
1 | # 查看 |
同时修改所有节点里面的/etc/sysconfig/network文件,保持与主机名一致
1 | # 查看 |
为了方便安装greenplum集群,且使greenplum自带的python不与系统的python版本相冲突,在每个节点中创建greenplum的用户和用户组
1 | groupadd -g 530 gpadmin |
1 | cat /etc/security/limits.conf |
1 | # 最新的centos好像这些都不需要操作 |
greenplum安装包到greenplum的官网上,下载greenplum安装包
或GitHub下载,点开Greenplum Database Server,根据自己的操作系统下载安装包,我下载当前最新的 greenplum-db-6.15.0-rhel7-x86_64.rpm,将其拷到master节点的/home/gpadmin目录中
版本快速链接: github:open-source-greenplum-db-6.15.0-rhel7-x86_64.rpm
master节点上安装greenplum切换到gpadmin用户
1 | su gpadmin |
docker1 | docker ps |
Rpm 安装1 | yum localinstall /home/gpadmin/open-source-greenplum-db-6.15.0-rhel7-x86_64.rpm -y |
1 | # 查看安装地址 |
gpssh-exkeys报错问题:cd /usr/bin
mv python python.bak
解压下载后的zip文件
1 | unzip greenplum-db-5.10.2-rhel7-x86_64.zip |
执行安装文件
1 | ./greenplum-db-5.10.2-rhel7-x86_64.bin |
安装期间需要配置安装目录,输入/home/gpadmin/greenplum-db-5.10.2
greenplum提供了批量操作节点的命令,通过指定配置文件使用批处理命令1 | cd ~/ ;mkdir conf |
greenplum-db/greenplum_path.sh中保存了运行greenplum的一些环境变量,包括GPHOME、PYTHONHOME等,在gpadmin账号下设置环境变量,并将master节点的key
交换到各个segment节点
1 | [gpadmin@mdw ~]$ source /home/gpadmin/greenplum-db/greenplum_path.sh |
注意:使用gpssh-exkeys命令时一定要使用gpadmin用户,因为会在/home/gpadmin/.ssh中生成ssh的免密码登录秘钥,如果使用其它账号登录,则会在其它账号下生成密钥,在gpadmin
账号下就无法使用gpssh的批处理命令
1 | [gpadmin@mdw ~]$ gpssh -f /home/gpadmin/conf/hostlist |
pwd命令是linux中的查看路径命令,在这里也是查看批量操作时各个节点当前所在的路径,从中可以看到已经成功连通了4个节点
打包master节点上的安装包
1 | [gpadmin@mdw ~]$ tar -czf gp.tar.gz greenplum-db-5.10.2 |
使用gpscp命令将这个文件复制到每个子节点
1 | [gpadmin@mdw ~]$ gpscp -f /home/gpadmin/conf/seg_hosts gp.tar.gz =:/home/gpadmin |
批量解压,并创建软链接
1 | [gpadmin@mdw ~]$ gpssh -f /home/gpadmin/conf/seg_hosts |
这样就完成了所有子节点数据库的安装
1 | [gpadmin@mdw ~]$ gpssh -f /home/gpadmin/conf/hostlist |
.bash_profile配置环境变量,并发送给其他子节点,确保这些环境变量生效1 | [gpadmin@mdw ~]$ vi .bash_profile |
1 | [gpadmin@mdw ~]$ vi /home/gpadmin/conf/gpinitsystem_config |
1 | [gpadmin@mdw ~]$ gpinitsystem -c /home/gpadmin/conf/gpinitsystem_config -s sdw3 |
其中,-s sdw3是指配置master的standby节点,然后按照提示步骤就能完成安装了
如果gpinitsystem不成功,在master节点的/home/gpadmin/gpAdminLogs目录下gpinitsystem_*
.log文件中查看日志信息,找出原因进行修改,然后再重新执行gpinitsystem进行初始化安装。
Citus以插件的方式扩展到postgresql中,独立于postgresql内核,所以能很快的跟上pg主版本的更新,部署也比较简单,是现在非常流行的分布式方案。Citus在苏宁有大规模应用,微软也提供citus的商业支持。下面是citus的架构:
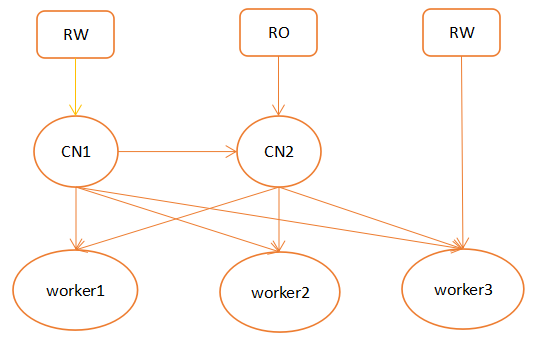
Citus
节点主要分为协调节点和工作节点,协调节点不存储真实数据,只存储数据分布的元信息,实际的数据被分成若干分片,打散到不同worker节点中,应用连接协调节点,协调节点进行sql解析,生成分布式执行计划,下发到worker节点执行,cn将结果汇总返回客户端。
Citus 的主要架构特点如下:
①有两种表类型:参考表和分布表,参考表每个协调节点和worker节点都有一份完整的副本,分布表则会打散分布到不同worker中。
②可以进行读写分离,如上图cn1为写节点,可以通过再增加多个cn读节点增加集群读的能力,写cn和读cn之间使用流复制进行元数据同步。
③支持MX模式,可以将元数据也存在某些worker节点中,这样使得该worker节点能够直接提供写的能力,以此增加集群写的能力。
④底层worker节点可以通过流复制搭建副本,保证数据高可用。
⑤做join时最好的结果是能够将计算下推到worker节点,但是只有在参考表和其他表做join以及两个表的分布方式相同的情况下才能下推到worker计算,否则需要将数据拉到协调节点进行计算。
⑥整体架构类似mycat的中间件,因为没有全局事务管理,故不能保证数据的实时读一致性,但是性能上相比要好。数据写一致性使用2pc来保证。
其它特性:
● PostgreSQL兼容
● 水平扩展
● 实时并发查
● 快速数据加载
● 实时增删改查
● 持分布式事务
● 支持常用DDL
Citus 性能参考(来自互联网)为了能够直观的了解citus分片表的性能优势,下面在1个CN和8个worker组成citus集群上, 对比普通表和分片表(96分片)的性能差异。
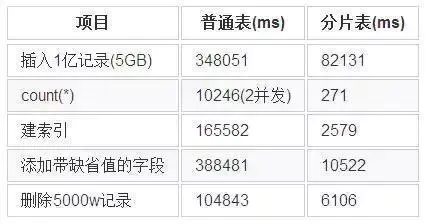
参考表:分片表主要解决的是大表的水平扩容问题,对数据量不是特别大又经常需要和分片表Join的维表可以采用一种特殊的分片策略,只分1个片且每个Worker上部署1个副本,这样的表叫做“参考表”。
itus不仅支持高速的批量数据加载(20w/s),还支持单条记录的实时增删改查。
查询数据时,CN对每一个涉及的分片开一个连接驱动所有相关worker同时工作。并且支持过滤,投影,聚合,join等常见算子的下推,尽可能减少CN的负载。所以,对于count(),sum()
这类简单的聚合计算,在128分片时citus可以轻松获得和PostgreSQL单并发相比50倍以上的性能提升。
和很多分布式数据库类似,citus对分片表间join的支持存在一定的限制。而多租户场景下每个租户的数据按租户ID分片,业务的SQL也带租户ID。因此这些SQL都可以直接下推到特定的分片上,避免了跨库join和跨库事务。
多租户定义:多租户技术或称多重租赁技术,简称SaaS,是一种软件架构技术,是实现如何在多用户环境下(此处的多用户一般是面向企业用户)共用相同的系统或程序组件,并且可确保各用户间数据的隔离性
。简单讲:在一台服务器上运行单个应用实例,它为多个租户(客户)提供服务。从定义中我们可以理解:多租户是一种架构,目的是为了让多用户环境下使用同一套程序,且保证用户间数据隔离。那么重点就很浅显易懂了,**
多租户的重点就是同一套程序下实现多用户数据的隔离**。
全球首个开源、多云、并行 大数据平台
Greenplum是pivotal公司推出的一款开源olap的mpp数据库,greenplum的用户在某种程度上甚至超越了pg,很多人可能是通过greenplum才认识的pg,可见greenplum的风靡。下面是greenplum架构:
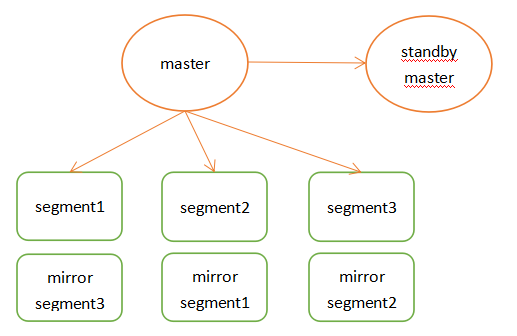
Master节点存储全局系统元数据信息,不存储真实数据。数据通过hash分布到不同的segment中,master作为sql的全局入口,负责在segment中分配工作负载,整合处理结果,返回客户端。
Greenplum架构特点如下:
①master节点可以做主备,segment节点也有镜像保证高可用,segment主备尽量混布到不同服务器上。
②支持行列混合存储引擎,同时支持外部表。
③在join时也涉及到数据跨节点重分布的问题,这也是share nothing数据库不可避免的问题。
④高速内部interconnect网络,实现数据join时的高速移动和汇总。
⑤高效的数据并行加载。
share nothingShared Everthting:一般是针对单个主机,完全透明共享CPU/MEMORY/IO,并行处理能力差,典型的代表SQLServer。 shared-everything架构优点很明显,但是网络,硬盘很容易就会成为系统瓶颈。
Shared Disk:各个处理单元使用自己的私有 CPU和Memory,共享磁盘系统。典型的代表Oracle Rac,
它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能 。
Shared Nothing
:各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。Share-Nothing架构在扩展性和成本上都具有明显优势。
大规模并行处理系统是由许多松耦合处理单元组成的,借助MPP这种高性能的系统架构,Greenplum可以将TB级的数据仓库负载分解,并使用所有的系统资源并行处理单个查询。
这里使用 SpringBoot 2.4.2 + kafka 2.7.0
1 | <!-- Springboot 建议使用 --> |
Kafka在属性文件格式中使用键值对进行配置。这些值可以通过文件或编程方式提供。 必备配置如下:
application.yml 配置
1 | spring |
1 | /** |
1 | public interface IKafkaService { |
1 |
|
1 |
|
输出结果
1 | 2021-01-26 15:40:33 DEBUG (KafkaTest.java:31)- 发送消息:test-topic-这是一个简单的消息! |
kafkaTemplate 提供了一个回调方法addCallback,可以在回调方法中监控消息是否发送成功,或失败时做补偿处理 有集中写法,这里简单的介绍两种 lambda和接口
1 |
|
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。其路由机制为:
partition,但指定了 key(kafka允许为每条消息设置一个key),则对key值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区;partition 和 key 都未指定,则使用kafka默认的分区策略,轮询选出一个 partition;※ 我们来自定义一个分区策略,将消息发送到我们指定的 partition,首先新建一个分区器类实现 Partitioner 接口,重写方法,其中partition方法的返回值就表示将消息发送到几号分区,
1 | public class CustomPartitioner implements Partitioner { |
在application.yml中配置自定义分区器,配置的值就是分区器类的全路径名,
1 | # 自定义分区器 |
kafka事务提交如果在发送消息时需要创建事务,可以使用 KafkaTemplate 的 executeInTransaction 方法来声明事务,
1 |
|
订阅 topic 是以组的形式进行的
partition 只能被消费一次。partition。partition,那么一定有监听空闲。1、指定topic、partition、offset消费
前面监听消费 topic 的时候,监听的是 topic 上所有的消息,如果想指定指定partition、指定offset来消费,直接配置@KafkaListener注解。
1 |
|
onMessage2监听的含义:监听 TEST_TOPIC 的0号分区,同时监听 TEST_TOPIC_2 的0号分区和 TEST_TOPIC_2 的1号分区里面 offset 从8开始的消息。
属性解释:
id:消费者ID;groupId:消费组ID;topics:监听的 topic,可监听多个;topicPartitions:可配置更加详细的监听信息,可指定 topic、partition、offset 监听。topics 和 topicPartitions 不能同时使用;最终结果会发现,onMessage1、onMessage2都可以消费 TEST_TOPIC 的消息。
设置 application.yml 开启批量消费即可,
1 | # 设置批量消费 |
接收消息时用List来接收,监听代码如下:
1 |
|
输出结果为
1 | 2021-01-26 20:23:20 DEBUG (KafkaConsumer.java:52)- 批量消费:topic:test-topic_3 partition:0 value:这是一个简单的消息! offset:10 |
ConsumerAwareListenerErrorHandler 异常处理器通过异常处理器,我们可以处理consumer在消费时发生的异常。 新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,用 @Bean 注入, 然后我们将这个异常处理器的 Bean
放到 @KafkaListener 注解的 errorHandler 属性里面,当监听抛出异常的时候,则会自动调用异常处理器,
1 |
|
执行看一下效果,
1 | 2021-01-26 20:36:34 DEBUG (KafkaConsumer.java:61)- 批量消费异常:topic:{test-topic_2=[Partition(topic = test-topic_2, partition = 0, leader = 0, replicas = [0], isr = [0], offlineReplicas = [])], test=[Partition(topic =******************************serialized key size = -1, serialized value size = 32, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 这是一个简单的消息_4!)] |
消息过滤器可以在消息抵达consumer之前被拦截,在实际应用中,我们可以根据自己的业务逻辑,筛选出需要的信息再交由 KafkaListener 处理,不需要的消息则过滤掉。 配置消息过滤只需要为 监听器工厂
配置一个 RecordFilterStrategy(消息过滤策略),返回 true 的时候消息将会被抛弃,返回 false 时,消息能正常抵达监听容器。
1 |
|
输出结果
1 | 2021-01-26 21:03:10 DEBUG (KafkaTest.java:96)- 发送完成 |
消息转发在实际开发中,应用A从TopicA 获取到消息,经过处理后转发到TopicB, 再由应用B监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
在SpringBoot集成Kafka实现消息的转发,只需要通过一个@SendTo 注解,被注解方法的return值即转发的消息内容,如下,
1 |
|
输出结果,如果结果不同,可以查看自己设置的延时时间及配置
1 | 2021-01-30 14:26:29 DEBUG (KafkaConsumer.java:122)- 消息转发 6:topic:test-topic_6 partition:0 value:这是一个简单的消息_6! offset:10 |
默认情况下,当消费者项目启动的时候,监听器就开始工作,监听消费发送到指定topic的消息, 那如果我们不想让监听器立即工作,想让它在我们指定的时间点开始工作,
或者在我们指定的时间点停止工作,使用 KafkaListenerEndpointRegistry
实现:
1 |
|
运行结果,
pause 时,延迟1秒,可能消息会被接收到,与设想的不一样,可以调用 isConsumerPaused查看消息是否被暂停)kafka 服务还在,所以消息是发送成功的。pause()方法在下一次poll()之前生效,而resume()方法在当前的poll()之后生效。当一个容器被暂停,它会继续拉取消费者,避免再均衡(如果组管理有使用),但是不会索取任何记录。pause后延迟5秒的结果:
1 | 2021-02-01 11:44:22 DEBUG (KafkaServiceImpl.java:30)- 消息发送成功:message:监听 7 默认未未启动,这是一个简单的消息_7! topic:test-topic_7 partition:0 offset:11 |
pause后延迟1秒的结果:
1 | 2021-02-01 11:39:59 DEBUG (KafkaServiceImpl.java:30)- 消息发送成功:message:监听 7 默认未未启动,这是一个简单的消息_7! topic:test-topic_7 partition:0 offset:7 |
测试同一组、不同组消费同一个 topic的partition
查看 topic:bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test-topic_8
1 | Topic: test-topic_8 PartitionCount: 1 ReplicationFactor: 1 Configs: |
当前 topic 只有一个 partition。
测试前把当前 kafka 配置改为立即发送,并且设置不多发。
1 | spring: |
测试代码
1 |
|
测试结果
1 | 2021-02-01 15:40:43 DEBUG (KafkaTest.java:172)- 发送完成 |
也就是意味着group8中的两个监听只有一个监听到轮数据。
以下来自简书
kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
kafka对外使用topic的概念,生产者往topic里写消息,消费者从读消息。为了做到水平扩展,一个topic实际是由多个partition组成的,遇到瓶颈时,可以通过增加partition的数量来进行横向扩容。单个parition内是保证消息有序。
每新写一条消息,kafka就是在对应的文件append写,所以性能非常高。
kafka的总体数据流是这样的:

kafka data flow
大概用法就是,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,然后进行业务处理。
图中有两个topic,topic 0有两个partition,topic 1有一个partition,三副本备份。可以看到consumer gourp 1中的consumer 2没有分到partition处理,这是有可能出现的,下面会讲到。
关于broker、topics、partitions的一些元信息用zk来存,监控和路由啥的也都会用到zk。
基本流程是这样的:

kafka sdk product flow.png
创建一条记录,记录中一个要指定对应的topic和value,key和partition可选。 先序列化,然后按照topic和partition,放进对应的发送队列中。kafka produce都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。
如果partition没填,那么情况会是这样的:
这些要发往同一个partition的请求按照配置,攒一波,然后由一个单独的线程一次性发过去。
有high level api,替我们把很多事情都干了,offset,路由啥都替我们干了,用以来很简单。
还有simple api,offset啥的都是要我们自己记录。
当存在多副本的情况下,会尽量把多个副本,分配到不同的broker上。kafka会为partition选出一个leader,之后所有该partition的请求,实际操作的都是leader,然后再同步到其他的follower。当一个broker歇菜后,所有leader在该broker上的partition都会重新选举,选出一个leader。(这里不像分布式文件存储系统那样会自动进行复制保持副本数)
然后这里就涉及两个细节:怎么分配partition,怎么选leader。
关于partition的分配,还有leader的选举,总得有个执行者。在kafka中,这个执行者就叫controller。kafka使用zk在broker中选出一个controller,用于partition分配和leader选举。
controller会在Zookeeper的/brokers/ids节点上注册Watch,一旦有broker宕机,它就能知道。当broker宕机后,controller就会给受到影响的partition选出新leader。controller从zk的/brokers/topics/[topic]/partitions/[partition]/state中,读取对应partition的ISR(in-sync replica已同步的副本)列表,选一个出来做leader。
选出leader后,更新zk,然后发送LeaderAndISRRequest给受影响的broker,让它们改变知道这事。为什么这里不是使用zk通知,而是直接给broker发送rpc请求,我的理解可能是这样做zk有性能问题吧。
如果ISR列表是空,那么会根据配置,随便选一个replica做leader,或者干脆这个partition就是歇菜。如果ISR列表的有机器,但是也歇菜了,那么还可以等ISR的机器活过来。
这里的策略,服务端这边的处理是follower从leader批量拉取数据来同步。但是具体的可靠性,是由生产者来决定的。
生产者生产消息的时候,通过request.required.acks参数来设置数据的可靠性。
| acks | what happen |
|---|---|
| 0 | which means that the producer never waits for an acknowledgement from the broker.发过去就完事了,不关心broker是否处理成功,可能丢数据。 |
| 1 | which means that the producer gets an acknowledgement after the leader replica has received the data. 当写Leader成功后就返回,其他的replica都是通过fetcher去同步的,所以kafka是异步写,主备切换可能丢数据。 |
| -1 | which means that the producer gets an acknowledgement after all in-sync replicas have received the data. 要等到isr里所有机器同步成功,才能返回成功,延时取决于最慢的机器。强一致,不会丢数据。 |
在acks=-1的时候,如果ISR少于min.insync.replicas指定的数目,那么就会返回不可用。
这里ISR列表中的机器是会变化的,根据配置replica.lag.time.max.ms,多久没同步,就会从ISR列表中剔除。以前还有根据落后多少条消息就踢出ISR,在1.0版本后就去掉了,因为这个值很难取,在高峰的时候很容易出现节点不断的进出ISR列表。
从ISA中选出leader后,follower会从把自己日志中上一个高水位后面的记录去掉,然后去和leader拿新的数据。因为新的leader选出来后,follower上面的数据,可能比新leader多,所以要截取。这里高水位的意思,对于partition和leader,就是所有ISR中都有的最新一条记录。消费者最多只能读到高水位;
从leader的角度来说高水位的更新会延迟一轮,例如写入了一条新消息,ISR中的broker都fetch到了,但是ISR中的broker只有在下一轮的fetch中才能告诉leader。
也正是由于这个高水位延迟一轮,在一些情况下,kafka会出现丢数据和主备数据不一致的情况,0.11开始,使用leader epoch来代替高水位。(https://cwiki.apache.org/confluence/display/KAFKA/KIP-101+-+Alter+Replication+Protocol+to+use+Leader+Epoch+rather+than+High+Watermark+for+Truncation#KIP-101-AlterReplicationProtocoltouseLeaderEpochratherthanHighWatermarkforTruncation-Scenario1:HighWatermarkTruncationfollowedbyImmediateLeaderElection)
*思考:*
当acks=-1时
订阅topic是以一个消费组来订阅的,一个消费组里面可以有多个消费者。同一个消费组中的两个消费者,不会同时消费一个partition。换句话来说,就是一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。因此,如果消费组内的消费者如果比partition多的话,那么就会有个别消费者一直空闲。

untitled_page.png
订阅topic时,可以用正则表达式,如果有新topic匹配上,那能自动订阅上。
一个消费组消费partition,需要保存offset记录消费到哪,以前保存在zk中,由于zk的写性能不好,以前的解决方法都是consumer每隔一分钟上报一次。这里zk的性能严重影响了消费的速度,而且很容易出现重复消费。
在0.10版本后,kafka把这个offset的保存,从zk总剥离,保存在一个名叫__consumeroffsets topic的topic中。写进消息的key由groupid、topic、partition组成,value是偏移量offset。topic配置的清理策略是compact。总是保留最新的key,其余删掉。一般情况下,每个key的offset都是缓存在内存中,查询的时候不用遍历partition,如果没有缓存,第一次就会遍历partition建立缓存,然后查询返回。
确定consumer group位移信息写入__consumers_offsets的哪个partition,具体计算公式:
1 | __consumers_offsets partition = |
*思考:*
如果正在跑的服务,修改了offsets.topic.num.partitions,那么offset的保存是不是就乱套了?
生产过程中broker要分配partition,消费过程这里,也要分配partition给消费者。类似broker中选了一个controller出来,消费也要从broker中选一个coordinator,用于分配partition。
下面从顶向下,分别阐述一下
这里我们可以看到,consumer group的coordinator,和保存consumer group offset的partition leader是同一台机器。
把coordinator选出来之后,就是要分配了
整个流程是这样的:
当partition或者消费者的数量发生变化时,都得进行 reblance。
列举一下会 reblance 的情况:
partitioncoordinator 自己也宕机了kafka支持3种消息投递语义
At most once:最多一次,消息可能会丢失,但不会重复
At least once:最少一次,消息不会丢失,可能会重复
Exactly once:只且一次,消息不丢失不重复,只且消费一次(0.11中实现,仅限于下游也是kafka)
在业务中,常常都是使用At least once的模型,如果需要可重入的话,往往是业务自己实现。
先获取数据,再进行业务处理,业务处理成功后commit offset。
1、生产者生产消息异常,消息是否成功写入不确定,重做,可能写入重复的消息
2、消费者处理消息,业务处理成功后,更新offset失败,消费者重启的话,会重复消费
先获取数据,再commit offset,最后进行业务处理。
1、生产者生产消息异常,不管,生产下一个消息,消息就丢了
2、消费者处理消息,先更新offset,再做业务处理,做业务处理失败,消费者重启,消息就丢了
思路是这样的,首先要保证消息不丢,再去保证不重复。所以盯着At least once的原因来搞。 首先想出来的:
由于业务接口是否幂等,不是kafka能保证的,所以kafka这里提供的exactly once是有限制的,消费者的下游也必须是kafka。所以一下讨论的,没特殊说明,消费者的下游系统都是kafka(注:使用kafka conector,它对部分系统做了适配,实现了exactly once)。
生产者幂等性好做,没啥问题。
解决重复消费有两个方法:
本来exactly once实现第1点就ok了。
但是在一些使用场景下,我们的数据源可能是多个topic,处理后输出到多个topic,这时我们会希望输出时要么全部成功,要么全部失败。这就需要实现事务性。既然要做事务,那么干脆把重复消费的问题从根源上解决,把commit offset和输出到其他topic绑定成一个事务。
思路是这样的,为每个producer分配一个pid,作为该producer的唯一标识。producer会为每一个<topic,partition>维护一个单调递增的seq。类似的,broker也会为每个<pid,topic,partition>记录下最新的seq。当req_seq == broker_seq+1时,broker才会接受该消息。因为:
消息的seq比broker的seq大超过时,说明中间有数据还没写入,即乱序了。
消息的seq不比broker的seq小,那么说明该消息已被保存。

解决重复生产
场景是这样的:
其中第2、3点作为一个事务,要么全成功,要么全失败。这里得益与offset实际上是用特殊的topic去保存,这两点都归一为写多个topic的事务性处理。

基本思路是这样的:
引入tid(transaction id),和pid不同,这个id是应用程序提供的,用于标识事务,和producer是谁并没关系。就是任何producer都可以使用这个tid去做事务,这样进行到一半就死掉的事务,可以由另一个producer去恢复。
同时为了记录事务的状态,类似对offset的处理,引入transaction coordinator用于记录transaction log。在集群中会有多个transaction coordinator,每个tid对应唯一一个transaction coordinator。
注:transaction log删除策略是compact,已完成的事务会标记成null,compact后不保留。
做事务时,先标记开启事务,写入数据,全部成功就在transaction log中记录为prepare commit状态,否则写入prepare abort的状态。之后再去给每个相关的partition写入一条marker(commit或者abort)消息,标记这个事务的message可以被读取或已经废弃。成功后在transaction log记录下commit/abort状态,至此事务结束。
数据流:

Kafka Transactions Data Flow.png
首先使用tid请求任意一个broker(代码中写的是负载最小的broker),找到对应的transaction coordinator。
请求transaction coordinator获取到对应的pid,和pid对应的epoch,这个epoch用于防止僵死进程复活导致消息错乱,当消息的epoch比当前维护的epoch小时,拒绝掉。tid和pid有一一对应的关系,这样对于同一个tid会返回相同的pid。
client先请求transaction coordinator记录<topic,partition>的事务状态,初始状态是BEGIN,如果是该事务中第一个到达的<topic,partition>,同时会对事务进行计时;client输出数据到相关的partition中;client再请求transaction coordinator记录offset的<topic,partition>事务状态;client发送offset commit到对应offset partition。
client发送commit请求,transaction coordinator记录prepare commit/abort,然后发送marker给相关的partition。全部成功后,记录commit/abort的状态,最后这个记录不需要等待其他replica的ack,因为prepare不丢就能保证最终的正确性了。
这里prepare的状态主要是用于事务恢复,例如给相关的partition发送控制消息,没发完就宕机了,备机起来后,producer发送请求获取pid时,会把未完成的事务接着完成。
当partition中写入commit的marker后,相关的消息就可被读取。所以kafka事务在prepare commit到commit这个时间段内,消息是逐渐可见的,而不是同一时刻可见。
前面都是从生产的角度看待事务。还需要从消费的角度去考虑一些问题。
消费时,partition中会存在一些消息处于未commit状态,即业务方应该看不到的消息,需要过滤这些消息不让业务看到,kafka选择在消费者进程中进行过来,而不是在broker中过滤,主要考虑的还是性能。kafka高性能的一个关键点是zero copy,如果需要在broker中过滤,那么势必需要读取消息内容到内存,就会失去zero copy的特性。
kafka的数据,实际上是以文件的形式存储在文件系统的。topic下有partition,partition下有segment,segment是实际的一个个文件,topic和partition都是抽象概念。
在目录/${topicName}-{$partitionid}/下,存储着实际的log文件(即segment),还有对应的索引文件。
每个segment文件大小相等,文件名以这个segment中最小的offset命名,文件扩展名是.log;segment对应的索引的文件名字一样,扩展名是.index。有两个index文件,一个是offset index用于按offset去查message,一个是time index用于按照时间去查,其实这里可以优化合到一起,下面只说offset index。总体的组织是这样的:

kafka 文件组织.png
为了减少索引文件的大小,降低空间使用,方便直接加载进内存中,这里的索引使用稀疏矩阵,不会每一个message都记录下具体位置,而是每隔一定的字节数,再建立一条索引。 索引包含两部分,分别是baseOffset,还有position。
baseOffset:意思是这条索引对应segment文件中的第几条message。这样做方便使用数值压缩算法来节省空间。例如kafka使用的是varint。
position:在segment中的绝对位置。
查找offset对应的记录时,会先用二分法,找出对应的offset在哪个segment中,然后使用索引,在定位出offset在segment中的大概位置,再遍历查找message。
| 配置项 | 作用 |
|---|---|
| broker.id | broker的唯一标识 |
| auto.create.topics.auto | 设置成true,就是遇到没有的topic自动创建topic。 |
| log.dirs | log的目录数,目录里面放partition,当生成新的partition时,会挑目录里partition数最少的目录放。 |
| 配置项 | 作用 |
|---|---|
| num.partitions | 新建一个topic,会有几个partition。 |
| log.retention.ms | 对应的还有minutes,hours的单位。日志保留时间,因为删除是文件维度而不是消息维度,看的是日志文件的mtime。 |
| log.retention.bytes | partion最大的容量,超过就清理老的。注意这个是partion维度,就是说如果你的topic有8个partition,配置1G,那么平均分配下,topic理论最大值8G。 |
| log.segment.bytes | 一个segment的大小。超过了就滚动。 |
| log.segment.ms | 一个segment的打开时间,超过了就滚动。 |
| message.max.bytes | message最大多大 |
关于日志清理,默认当前正在写的日志,是怎么也不会清理掉的。
还有0.10之前的版本,时间看的是日志文件的mtime,但这个指是不准确的,有可能文件被touch一下,mtime就变了。因此在0.10版本开始,改为使用该文件最新一条消息的时间来判断。
按大小清理这里也要注意,Kafka在定时任务中尝试比较当前日志量总大小是否超过阈值至少一个日志段的大小。如果超过但是没超过一个日志段,那么就不会删除。
kafka 可以通过官网下载
kafka 根据Scala版本不同,又分为多个版本,我不需要使用Scala,所以就下载官方推荐版本kafka_2.13-2.7.0.tgz。
解压到opt目录下
1 | wget https://downloads.apache.org/kafka/3.2.1/kafka_2.13-3.2.1.tgz |
kafka的安装需要依赖Zookeeper。
Zookeeperkafka自带的Zookeeper程序使用bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停止Zookeeper。
Zookeeper的配制文件是config/zookeeper.properties,可以修改其中的参数
Zookeeper1 | # 修改默认端口 |
-daemon参数,可以在后台启动Zookeeper,输出的信息在保存在执行目录的logs/zookeeper.out文件中。问题:对于小内存的服务器,启动时有可能会出现如下错误。
os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)可以通过修改
bin/zookeeper-server-start.sh中的参数,来减少内存的使用,将-Xmx512M -Xms512M改小。
Zookeeper1 | ~/kafka/bin/zookeeper-server-stop.sh -daemon ~/kafka/config/zookeeper.properties |
kafka的配置文件在config/server.properties文件中,主要修改参数如下,更具体的参数说明以后再整理下。
broker.id是kafka broker的编号,集群里每个broker的id需不同。默认从0开始。listeners是监听地址,需要提供外网服务的话,要设置本地的IP地址log.dirs是日志目录,需要设置Zookeeper集群地址,我是在同一个服务器上搭建了kafka和Zookeeper,所以填的本地地址num.partitions 为新建Topic的默认Partition数量,partition数量提升,一定程度上可以提升并发性,数值应该小于等于broker的数量kafka集群,所以kafka的所有文件都复制两份,配置文件做相应的修改,尤其是brokerid、IP地址和log.dirs。分别创建软链接kafka1和kafka2。1 | # 集群里每个`broker`的`id`需不同。默认从0开始。 |
kafka1 | ~/kafka/bin/kafka-server-start.sh -daemon ~/kafka/config/server.properties |
-daemon 参数会将任务转入后台运行,输出日志信息将写入日志文件,查看 logs/kafkaServer.out,如果结尾输同started说明启动成功。
也可以用ps -ef|grep kafka命令,看有没有kafka的进程
kafka默认的xmx xms都是1G, 对于小内存的服务器,启动时有可能会出现如下错误。
os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)可以通过修改
bin/kafka-server-start.sh中的参数,来减少内存的使用,将配置改为-Xmx256M -Xms64M。
kafka1 | ~/kafka/bin/kafka-server-stop.sh -daemon ~/kafka/config/server.properties |
前提:kafka和Zookeeper已启动完成
创建一个名为 test 的Topic,只有一个备份(replication-facto)和一个分区(partitions)。
1 | ~/kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.14.123:49092 --replication-factor 1 --partitions 1 --topic test |
成功提示 Created topic test.
1 | ~/kafka/bin/kafka-topics.sh --list --bootstrap-server 192.168.14.123:49092 |
成功提示
test
Kafka提供了一个命令行的工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群。每一行是一条消息。
运行producer(生产者),然后在控制台输入几条消息到服务器。
1 | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.14.123:49092 --topic test |
1 | ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.123:49092 --topic test --from-beginning |
展示上面输入的两个消息,表示成功;
--from-beginning 是从开始的消息展示1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --describe --topic test |
1 | Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs: |
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --delete --topic test |
broker集群一个 broker只是集群中的一个节点,id是这个节点的名称。
1 | cp ~/kafka/config/server.properties ~/kafka/config/server-1.properties |
修改每个配置的 id,id 从0开始。
简单的配置如下
server-1.properties
1 | # 修改节点名称 |
server-2.properties
1 | # 修改节点名称 |
1 | ~/kafka/bin/kafka-server-start.sh -daemon ~/kafka/config/server-1.properties |
1 | ~/kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.14.123:49092 --replication-factor 3 --partitions 1 --topic my-replicated-3-topic |
成功提示:`Created topic my-replicated-3-topic.
这时候已经完成了一个集群的配置。
启动失败解决
如果报
replication不够的错误,则是因为server1、server2可能启动失败了。可以把
-daemon参数删掉,然后执行命令查看错误bin/kafka-server-start.sh config/server-1.properties;可以直接查看日志
logs/server.out;
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --describe --topic my-replicated-3-topic |
1 | Topic: my-replicated-3-topic PartitionCount: 1 ReplicationFactor: 3 Configs: |
leader: 1表示当前 leader在节点1上。
1 | ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.123:49092 --topic my-replicated-3-topic |
1 | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.14.123:49092 --topic my-replicated-3-topic |
leader崩溃leader11 | # 查询进程 |
1 | ~/kafka/bin/kafka-topics.sh --describe --broker-list 192.168.14.123:49092 --topic my-replicated-3-topic |
此时的 leader已经变为了 0,所以 broker 0 成为了 leader, broker1已经不在备份集合里了。
1 | Topic: my-replicated-3-topic PartitionCount: 1 ReplicationFactor: 3 Configs: |
1 | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.14.123:49094 --topic my-replicated-3-topic |
1 | ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.123:49092 --topic my-replicated-3-topic --from-beginning |
这个时候会发现所有的消息都没有丢
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --delete --topic my-replicated-3-topic |
当前下载的kafka程序里自带Zookeeper,可以直接使用其自带的Zookeeper建立集群,也可以单独使用Zookeeper安装文件建立集群。
Zookeeper的安装及配置可以参考另一篇博客,里面有详细介绍
https://www.cnblogs.com/zhaoshizi/p/12105143.html
一个典型的Kafka集群中包含若干Produce,若干broker(一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。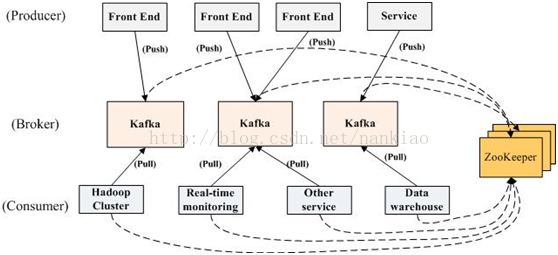
1)Producer端直接连接broker.list列表,从列表中返回TopicMetadataResponse,该Metadata包含Topic下每个partition leader建立socket连接并发送消息.
2)Broker端使用zookeeper用来注册broker信息,以及监控partition leader存活性.
3)Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
Zookeeper作用:管理broker、consumer
创建Broker后,向zookeeper注册新的broker信息,实现在服务器正常运行下的水平拓展。具体的,通过注册watcher,获取partition的信息。
Topic的注册,zookeeper会维护topic与broker的关系,通/brokers/topics/topic.name节点来记录。
Producer向zookeeper中注册watcher,了解topic的partition的消息,以动态了解运行情况,实现负载均衡。Zookeepr不管理producer,只是能够提供当前broker的相关信息。
Consumer可以使用group形式消费kafka中的数据。所有的group将以轮询的方式消费broker中的数据,具体的按照启动的顺序。Zookeeper会给每个consumer group一个ID,即同一份数据可以被不同的用户ID多次消费。因此这就是单播与多播的实现。以单个消费者还是以组别的方式去消费数据,由用户自己去定义。Zookeeper管理consumer的offset跟踪当前消费的offset。
kafka使用ZooKeeper用于管理、协调代理。每个Kafka代理通过Zookeeper协调其他Kafka代理。
当Kafka系统中新增了代理或某个代理失效时,Zookeeper服务将通知生产者和消费者。生产者与消费者据此开始与其他代理协调工作。
Zookeeper在Kakfa中扮演的角色:Kafka将元数据信息保存在Zookeeper中,但是发送给Topic本身的数据是不会发到Zk上的
· kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在zookeeper注册并保持相关的元数据(topic,partition信息等)更新。
· 而客户端会在zookeeper上注册相关的watcher。一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除 broker时,各broker间仍能自动实现负载均衡。这里的客户端指的是Kafka的消息生产端(Producer)和消息消费端(Consumer)
· Broker端使用zookeeper来注册broker信息,以及监测partitionleader存活性.
· Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partitionleader建立socket连接,并获取消息.
· Zookeer和Producer没有建立关系,只和Brokers、Consumers建立关系以实现负载均衡,即同一个ConsumerGroup中的Consumers可以实现负载均衡(因为Producer是瞬态的,可以发送后关闭,无需直接等待)
从控制台写入和写回数据是一个方便的开始,但你可能想要从其他来源导入或导出数据到其他系统。对于大多数系统,可以使用kafka Connect,而不需要编写自定义集成代码。
Kafka Connect是导入和导出数据的一个工具。是一个在 kafka与其他系统之间的可扩展和可靠的流数据工具。它使得快速定义连接器变得非常简单,这些连接器可以将大量数据移入和移出Kafka。Kafka Connect
可以摄取整个数据库或者从你所有的应用服务器上收集指标到Kafka主题中,使数据可以用于低延迟的流处理。导出作业可以将数据从Kafka主题交付到二级存储和查询系统,或者交付到批处理系统以进行离线分析。
一些概念
kafka connector:是kafka connect的关键组成部分,它是一个逻辑上的job,用于在kafka和其他系统之间拷贝数据,比如:从上游系统拷贝数据到kafka,或者从kafka拷贝数据到下游系统
Tasks:每个kafka connector可以初始化一组task进行数据的拷贝
Workers:逻辑上包含kafka connector和tasks用来调度执行具体任务的进程,具体执行时分为standalone模式和distributed模式
下面介绍配置、运行和管理Kafka Connect。
Kafka Connect目前支持两种执行模式:单机(单进程)和分布式。
在独立模式下,所有工作都在单个进程中执行。这种配置更容易设置和开始,可能在只有一个worker有意义的情况下有用(例如收集日志文件),但它没有从Kafka Connect的一些特性中受益,比如容错。可以使用如下命令启动独立进程:
1 | bin/connect-standalone.sh config/connect-standalone.properties connector1.properties [connector2.properties ...] |
配置文件在 config/connect-standalone.properties
首先是Kafka Connect处理的配置,包含常见的配置,例如要连接的Kafka broker和数据的序列化格式。其余的配置文件都指定了要创建的连接器。包括连接器唯一名称,和要实例化的连接器类。以及连接器所需的任何其他配置。
1 | # 连接器的唯一名称。再次尝试注册相同名称将会失败。 |
在这个快速入门里,我们将看到如何运行Kafka Connect用简单的连接器从文件导入数据到Kafka主题,再从Kafka主题导出数据到文件。
首先,我们首先创建一些种子数据用来测试:
1 | echo -e "foo\nbar" > test.txt |
接下来,我们开始2个连接器运行在独立的模式,这意味着它们运行在一个单一的,本地的,专用的进程。我们提供3个配置文件作为参数。
1 | bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties |
这些包含在Kafka中的示例配置文件使用之前启动的默认本地群集配置,并创建两个连接器: 第一个是源连接器,用于从输入文件读取行,并将其输入到 Kafka topic。 第二个是接收器连接器,它从Kafka
topic中读取消息,并在输出文件中生成一行。
在启动过程中,你会看到一些日志消息,包括一些连接器正在实例化的指示。 一旦Kafka Connect进程启动,源连接器就开始从test.txt读取行并且 将它们生产到主题connect-test
中,同时接收器连接器也开始从主题connect-test中读取消息, 并将它们写入文件test.sink.txt中。我们可以通过检查输出文件的内容来验证数据是否已通过整个pipeline进行交付:
1 | more test.sink.txt |
出现结果
1 | foo |
请注意,数据存储在Kafka topicconnect-test中,因此我们也可以运行一个console consumer(控制台消费者)来查看 topic 中的数据(或使用custom
consumer(自定义消费者)代码进行处理):
1 | bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning |
结果:
1 | {"schema":{"type":"string","optional":false},"payload":"foo"} |
连接器一直在处理数据,所以我们可以将数据添加到文件中,并看到它在pipeline 中移动:
1 | # 追加一行数据 |
应该可以看到这一行出现在控制台用户输出和接收器文件中。
MySql 操作https://www.pianshen.com/article/3877182847/
| NAME | DESCRIPTION | TYPE | DEFAULT | VALID VALUES | IMPORTANCE |
|---|---|---|---|---|---|
| config.storage.topic | kafka topic仓库配置 | string | high | ||
| group.id | 唯一的字符串,用于标识此worker所属的Connect集群组。 | string | high | ||
| key.converter | 用于Kafka Connect和写入到Kafka的序列化消息的之间格式转换的转换器类。 这可以控制写入或从kafka读取的消息中的键的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 | class | high | ||
| offset.storage.topic | 连接器的offset存储到哪个topic中 | string | high | ||
| status.storage.topic | 追踪连接器和任务状态存储到哪个topic中 | string | high | ||
| value.converter | 用于Kafka Connect格式和写入Kafka的序列化格式之间转换的转换器类。 控制了写入或从Kafka读取的消息中的值的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 | class | high | ||
| internal.key.converter | 用于在Kafka Connect格式和写入Kafka的序列化格式之间转换的转换器类。 这可以控制写入或从Kafka读取的消息中的key的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 此设置用于控制框架内部使用的记账数据的格式,例如配置和偏移量,因此用户可以使用运行各种Converter实现。 | class | low | ||
| internal.value.converter | 用于在Kafka Connect格式和写入Kafka的序列化格式之间转换的转换器类。 这控制了写入或从Kafka读取的消息中的值的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 此设置用于控制框架内部使用的记账数据的格式,例如配置和偏移量,因此用户可以使用运行各种Converter实现。 | class | low | ||
| bootstrap.servers | 用于建立与Kafka集群的初始连接的主机/端口列表。此列表用来发现完整服务器集的初始主机。 该列表的格式应为host1:port1,host2:port2,….由于这些服务器仅用于初始连接以发现完整的集群成员资格(可能会动态更改),因此,不需要包含完整的服务器(尽管如此,你需要多配置几个,以防止配置的宕机)。 | list | localhost:9092 | high | |
| heartbeat.interval.ms | 心跳间隔时间。心跳用于确保会话保持活动,并在新成员加入或离开组时进行重新平衡。 该值必须设置为低于session.timeout.ms,但通常应设置为不高于该值的1/3。 | int | 3000 | high | |
| rebalance.timeout.ms | 限制所有组中消费者的任务处理数据和提交offset所需的时间。如果超时,那么woker将从组中删除,这也将导致offset提交失败。 | int | 60000 | high | |
| session.timeout.ms | 用于察觉worker故障的超时时间。worker定时发送心跳以表明自己是活着的。如果broker在会话超时时间到期之前没有接收到心跳,那么broker将从分组中移除该worker,并启动重新平衡。注意,该值必须在group.min.session.timeout.ms和group.max.session.timeout.ms范围内。 |
int | 10000 | high | |
| ssl.key.password | 密钥存储文件中私钥的密码。 这对于客户端是可选的。 | password | null | high | |
| ssl.keystore.location | 密钥存储文件的位置。 这对于客户端是可选的,可以用于客户端的双向身份验证。 | string | null | high | |
| ssl.keystore.password | 密钥存储文件的存储密码。 客户端是可选的,只有配置了ssl.keystore.location才需要。 | password | null | high | |
| ssl.truststore.location | 信任存储文件的位置。 | string | null | high | |
| ssl.truststore.password | 信任存储文件的密码。 | password | null | high | |
| connections.max.idle.ms | 多少毫秒之后关闭空闲的连接。 | long | 540000 | medium | |
| receive.buffer.bytes | 读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。 如果值为-1,则将使用OS默认值。 | int | 32768 | [0,…] | medium |
| request.timeout.ms | 配置控制客户端等待请求响应的最长时间。 如果在超时之前未收到响应,客户端将在必要时重新发送请求,如果重试耗尽,则该请求将失败。 | int | 40000 | [0,…] | medium |
| sasl.jaas.config | 用于JAAS配置文件的SASL连接的JAAS登录上下文参数格式。这里描述了JAAS配置文件的格式。该值的格式为:’ (=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | Kafka运行的Kerberos principal名称。 可以在Kafka的JAAS配置或Kafka的配置中定义。 | string | null | medium | |
| sasl.mechanism | 用户客户端连接的SASL机制。可以提供者任何安全机制。 GSSAPI是默认机制。 | string | GSSAPI | medium | |
| security.protocol | 用于和broker通讯的策略。有效的值有:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL。 | string | PLAINTEXT | medium | |
| send.buffer.bytes | 发送数据时使用TCP发送缓冲区(SO_SNDBUF)的大小。如果值为-1,则将使用OS默认。 | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | 启用SSL连接的协议列表。 | list | TLSv1.2,TLSv1 .1,TLSv1 | medium | |
| ssl.keystore.type | 密钥存储文件的文件格式。 对于客户端是可选的。 | string | JKS | medium | |
| ssl.protocol | 用于生成SSLContext的SSL协议。 默认设置是TLS,这对大多数情况都是适用的。 最新的JVM中的允许值为TLS,TLSv1.1和TLSv1.2。 旧的JVM可能支持SSL,SSLv2和SSLv3,但由于已知的安全漏洞,不建议使用SSL。 | string | TLS | medium | |
| ssl.provider | 用于SSL连接的安全提供程序的名称。 默认值是JVM的默认安全提供程序。 | string | null | medium | |
| ssl.truststore.type | 信任存储文件的文件格式。 | string | JKS | medium | |
| worker.sync.timeout.ms | 当worker与其他worker不同步并需要重新同步配置时,需等待一段时间才能离开组,然后才能重新加入。 | int | 3000 | medium | |
| worker.unsync.backoff.ms | 当worker与其他worker不同步,并且无法在worker.sync.timeout.ms 期间追赶上,在重新连接之前,退出Connect集群的时间。 | int | 300000 | medium | |
| access.control.allow.methods | 通过设置Access-Control-Allow-Methods标头来设置跨源请求支持的方法。 Access-Control-Allow-Methods标头的默认值允许GET,POST和HEAD的跨源请求。 | string | “” | low | |
| access.control.allow.origin | 将Access-Control-Allow-Origin标头设置为REST API请求。要启用跨源访问,请将其设置为应该允许访问API的应用程序的域,或者 *” 以允许从任何的域。 默认值只允许从REST API的域访问。 |
string | “” | low | |
| client.id | 在发出请求时传递给服务器的id字符串。这样做的目的是通过允许逻辑应用程序名称包含在请求消息中,来跟踪请求来源。而不仅仅是ip/port | string | “” | low | |
| config.storage.replication.factor | 当创建配置仓库topic时的副本数 | short | 3 | [1,…] | low |
| metadata.max.age.ms | 在没有任何分区leader改变,主动地发现新的broker或分区的时间。 | long | 300000 | [0,…] | low |
| metric.reporters | A list of classes to use as metrics reporters. Implementing the MetricReporter interface allows plugging in classes that will be notified of new metric creation. The JmxReporter is always included to register JMX statistics. | list | “” | low | |
| metrics.num.samples | 保留计算metrics的样本数(译者不清楚是做什么的) | int | 2 | [1,…] | low |
| metrics.sample.window.ms | The window of time a metrics sample is computed over. | long | 30000 | [0,…] | low |
| offset.flush.interval.ms | 尝试提交任务偏移量的间隔。 | long | 60000 | low | |
| offset.flush.timeout.ms | 在取消进程并恢复要在之后尝试提交的offset数据之前,等待消息刷新并分配要提交到offset仓库的offset数据的最大毫秒数。 | long | 5000 | low | |
| offset.storage.partitions | 创建offset仓库topic的分区数 | int | 25 | [1,…] | low |
| offset.storage.replication.factor | 创建offset仓库topic的副本数 | short | 3 | [1,…] | low |
| plugin.path | 包含插件(连接器,转换器,转换)逗号(,)分隔的路径列表。该列表应包含顶级目录,其中包括以下任何组合:a)包含jars与插件及其依赖关系的目录 b)具有插件及其依赖项的uber-jars c)包含插件类的包目录结构的目录及其依赖关系,注意配置:将遵循符号链接来发现依赖关系或插件。 示例:plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors | list | null | low | |
| reconnect.backoff.max.ms | 无法连接broker时等待的最大时间(毫秒)。如果设置,则每个host的将会持续的增加,直到达到最大值。计算增加后,再增加20%的随机抖动,以避免高频的反复连接。 | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | 尝试重新连接到主机之前等待的时间。 避免了高频率反复的连接主机。 这种机制适用于消费者向broker发送的所有请求。 | long | 50 | [0,…] | low |
| rest.advertised.host.name | 如果设置,其他wokers将通过这个hostname进行连接。 | string | null | low | |
| rest.advertised.port | 如果设置,其他的worker将通过这个端口进行连接。 | int | null | low | |
| rest.host.name | REST API的主机名。 如果设置,它将只绑定到这个接口。 | string | null | low | |
| rest.port | 用于监听REST API的端口 | int | 8083 | low | |
| retry.backoff.ms | 失败请求重新尝试之前的等待时间,避免了在某些故障的情况下,频繁的重复发送请求。 | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit命令路径. | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | 尝试refresh之间登录线程的休眠时间. | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | 添加到更新时间的随机抖动百分比。 | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将休眠,直到从上次刷新ticket到期,此时将尝试续订ticket。 | double | 0.8 | low | |
| ssl.cipher.suites | 密码套件列表。用于TLS或SSL网络协议协商网络连接的安全设置的认证,加密,MAC和密钥交换算法的命名组合。 默认情况下,支持所有可用的密码套件。 | list | null | low | |
| ssl.endpoint.identification.algorithm | 末端识别算法使用服务器证书验证服务器主机名。 | string | null | low | |
| ssl.keymanager.algorithm | 用于SSL连接的key管理工厂的算法,默认值是Java虚拟机配置的密钥管理工厂算法。 | string | SunX509 | low | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现。 | string | null | low | |
| ssl.trustmanager.algorithm | 用于SSL连接的信任管理仓库算法。默认值是Java虚拟机配置的信任管理器工厂算法。 | string | PKIX | low | |
| status.storage.partitions | 用于创建状态仓库topic的分区数 | int | 5 | [1,…] | low |
| status.storage.replication.factor | 用于创建状态仓库topic的副本数 | short | 3 | [1,…] | low |
| task.shutdown.graceful.timeout.ms | 等待任务正常关闭的时间,这是总时间,不是每个任务,所有任务触发关闭,然后依次等待。 | long | 5000 | low |
某天,不小心误删了 $HOME 路径下的数据。
网上找到了ext3grep尝试恢复;
安装
1 | sudo pacman -S ext3grep |
查看版本
1 | ext3grep -v |
输出下面信息
1 | Running ext3grep version 0.10.2 |
查看命令
1 | ext3grep --help |
查询要恢复文件的 inode 号
1 | ext3grep /dev/sda5 --ls --inode 10092546 |
查询最大 inode号
1 | ls -id |
失败
下载主题到 gnome-look 。
我这里下载的排名最高的 Tela grub
1 | sudo tar -xf 主题包名 |
1 | sudo cp -r 主题包名 /boot/grub/themes/ |
install.sh脚本1 | sudo sh Tela-2k/install.sh |
1 | sudo vim /etc/grub.d/00_header |
添加如下内容:
1 | GRUB_THEME="/boot/grub/themes/主题包名/theme.txt" |
1 | sudo grub-mkconfig -o /boot/grub/grub.cfg |
1 | # 这里是主题目录 |
修改其中的
1 | item_font="" |
改好保存就可以了。