Kafka安装配置
一、安装
kafka 可以通过官网下载
kafka 根据Scala版本不同,又分为多个版本,我不需要使用Scala,所以就下载官方推荐版本kafka_2.13-2.7.0.tgz。
解压到opt目录下
1 | wget https://downloads.apache.org/kafka/3.2.1/kafka_2.13-3.2.1.tgz |
kafka的安装需要依赖Zookeeper。
二、默认的Zookeeper
kafka自带的Zookeeper程序使用bin/zookeeper-server-start.sh,以及bin/zookeeper-server-stop.sh来启动和停止Zookeeper。
Zookeeper的配制文件是config/zookeeper.properties,可以修改其中的参数
(1)启动Zookeeper
1 | # 修改默认端口 |
-daemon参数,可以在后台启动Zookeeper,输出的信息在保存在执行目录的logs/zookeeper.out文件中。
问题:对于小内存的服务器,启动时有可能会出现如下错误。
os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)可以通过修改
bin/zookeeper-server-start.sh中的参数,来减少内存的使用,将-Xmx512M -Xms512M改小。
(2)关闭Zookeeper
1 | ~/kafka/bin/zookeeper-server-stop.sh -daemon ~/kafka/config/zookeeper.properties |
三、Kafka配置
kafka的配置文件在config/server.properties文件中,主要修改参数如下,更具体的参数说明以后再整理下。
broker.id是kafka broker的编号,集群里每个broker的id需不同。默认从0开始。listeners是监听地址,需要提供外网服务的话,要设置本地的IP地址log.dirs是日志目录,需要设置- 设置
Zookeeper集群地址,我是在同一个服务器上搭建了kafka和Zookeeper,所以填的本地地址 num.partitions为新建Topic的默认Partition数量,partition数量提升,一定程度上可以提升并发性,数值应该小于等于broker的数量- 因为要创建
kafka集群,所以kafka的所有文件都复制两份,配置文件做相应的修改,尤其是brokerid、IP地址和log.dirs。分别创建软链接kafka1和kafka2。
1 | # 集群里每个`broker`的`id`需不同。默认从0开始。 |
四、启动及停止Kafka
(1)启动kafka
1 | ~/kafka/bin/kafka-server-start.sh -daemon ~/kafka/config/server.properties |
-daemon 参数会将任务转入后台运行,输出日志信息将写入日志文件,查看 logs/kafkaServer.out,如果结尾输同started说明启动成功。
也可以用ps -ef|grep kafka命令,看有没有kafka的进程
kafka默认的xmx xms都是1G, 对于小内存的服务器,启动时有可能会出现如下错误。
os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)可以通过修改
bin/kafka-server-start.sh中的参数,来减少内存的使用,将配置改为-Xmx256M -Xms64M。
(2)停止kafka
1 | ~/kafka/bin/kafka-server-stop.sh -daemon ~/kafka/config/server.properties |
五、测试
前提:kafka和Zookeeper已启动完成
1、创建topic
创建一个名为 test 的Topic,只有一个备份(replication-facto)和一个分区(partitions)。
1 | ~/kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.14.123:49092 --replication-factor 1 --partitions 1 --topic test |
成功提示 Created topic test.
2、查看主题
1 | ~/kafka/bin/kafka-topics.sh --list --bootstrap-server 192.168.14.123:49092 |
成功提示
test
3、发送消息
Kafka提供了一个命令行的工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群。每一行是一条消息。
运行producer(生产者),然后在控制台输入几条消息到服务器。
1 | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.14.123:49092 --topic test |
4、接收消息
1 | ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.123:49092 --topic test --from-beginning |
展示上面输入的两个消息,表示成功;
--from-beginning是从开始的消息展示
5、查看特定主题的详细信息
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --describe --topic test |
1 | Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs: |
- “leader”是负责给定分区所有读写操作的节点。每个节点都是随机选择的部分分区的领导者。
- “replicas”是复制分区日志的节点列表,不管这些节点是leader还是仅仅活着。
- “isr”是一组“同步”replicas,是replicas列表的子集,它活着并被指到leader。
6、删除主题
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --delete --topic test |
六、设置多个broker集群
一个 broker只是集群中的一个节点,id是这个节点的名称。
1、创建多个节点的配置
1 | cp ~/kafka/config/server.properties ~/kafka/config/server-1.properties |
修改每个配置的 id,id 从0开始。
简单的配置如下
server-1.properties
1 | # 修改节点名称 |
server-2.properties
1 | # 修改节点名称 |
2、启动其它配置的服务
1 | ~/kafka/bin/kafka-server-start.sh -daemon ~/kafka/config/server-1.properties |
3、创建新的 topic
1 | ~/kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.14.123:49092 --replication-factor 3 --partitions 1 --topic my-replicated-3-topic |
成功提示:`Created topic my-replicated-3-topic.
这时候已经完成了一个集群的配置。
启动失败解决
如果报
replication不够的错误,则是因为server1、server2可能启动失败了。可以把
-daemon参数删掉,然后执行命令查看错误bin/kafka-server-start.sh config/server-1.properties;可以直接查看日志
logs/server.out;
4、查看主题列表
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --describe --topic my-replicated-3-topic |
1 | Topic: my-replicated-3-topic PartitionCount: 1 ReplicationFactor: 3 Configs: |
leader: 1表示当前 leader在节点1上。
5、收发消息测试
接收消息
1 | ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.123:49092 --topic my-replicated-3-topic |
发送消息
1 | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.14.123:49092 --topic my-replicated-3-topic |
6、测试集群 leader崩溃
停止 leader1
1 | # 查询进程 |
查看主题
1 | ~/kafka/bin/kafka-topics.sh --describe --broker-list 192.168.14.123:49092 --topic my-replicated-3-topic |
此时的 leader已经变为了 0,所以 broker 0 成为了 leader, broker1已经不在备份集合里了。
1 | Topic: my-replicated-3-topic PartitionCount: 1 ReplicationFactor: 3 Configs: |
发送消息测试
1 | ~/kafka/bin/kafka-console-producer.sh --broker-list 192.168.14.123:49094 --topic my-replicated-3-topic |
查询所有消息
1 | ~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.123:49092 --topic my-replicated-3-topic --from-beginning |
这个时候会发现所有的消息都没有丢
删除主题
1 | ~/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.14.123:49092 --delete --topic my-replicated-3-topic |
七、安全
Zookeeper配置
当前下载的kafka程序里自带Zookeeper,可以直接使用其自带的Zookeeper建立集群,也可以单独使用Zookeeper安装文件建立集群。
1. 单独使用Zookeeper安装文件建立集群
Zookeeper的安装及配置可以参考另一篇博客,里面有详细介绍
https://www.cnblogs.com/zhaoshizi/p/12105143.html
Kafka与Zookeeper的关系
一个典型的Kafka集群中包含若干Produce,若干broker(一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。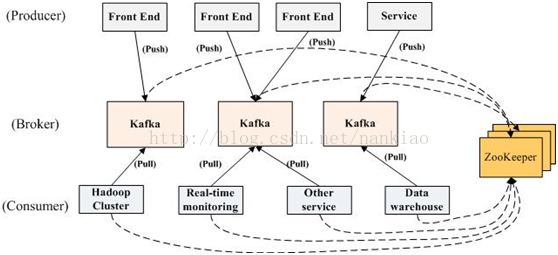
1)Producer端直接连接broker.list列表,从列表中返回TopicMetadataResponse,该Metadata包含Topic下每个partition leader建立socket连接并发送消息.
2)Broker端使用zookeeper用来注册broker信息,以及监控partition leader存活性.
3)Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息。
Zookeeper作用:管理broker、consumer
创建Broker后,向zookeeper注册新的broker信息,实现在服务器正常运行下的水平拓展。具体的,通过注册watcher,获取partition的信息。
Topic的注册,zookeeper会维护topic与broker的关系,通/brokers/topics/topic.name节点来记录。
Producer向zookeeper中注册watcher,了解topic的partition的消息,以动态了解运行情况,实现负载均衡。Zookeepr不管理producer,只是能够提供当前broker的相关信息。
Consumer可以使用group形式消费kafka中的数据。所有的group将以轮询的方式消费broker中的数据,具体的按照启动的顺序。Zookeeper会给每个consumer group一个ID,即同一份数据可以被不同的用户ID多次消费。因此这就是单播与多播的实现。以单个消费者还是以组别的方式去消费数据,由用户自己去定义。Zookeeper管理consumer的offset跟踪当前消费的offset。
kafka使用ZooKeeper用于管理、协调代理。每个Kafka代理通过Zookeeper协调其他Kafka代理。
当Kafka系统中新增了代理或某个代理失效时,Zookeeper服务将通知生产者和消费者。生产者与消费者据此开始与其他代理协调工作。
Zookeeper在Kakfa中扮演的角色:Kafka将元数据信息保存在Zookeeper中,但是发送给Topic本身的数据是不会发到Zk上的
· kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在zookeeper注册并保持相关的元数据(topic,partition信息等)更新。
· 而客户端会在zookeeper上注册相关的watcher。一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除 broker时,各broker间仍能自动实现负载均衡。这里的客户端指的是Kafka的消息生产端(Producer)和消息消费端(Consumer)
· Broker端使用zookeeper来注册broker信息,以及监测partitionleader存活性.
· Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partitionleader建立socket连接,并获取消息.
· Zookeer和Producer没有建立关系,只和Brokers、Consumers建立关系以实现负载均衡,即同一个ConsumerGroup中的Consumers可以实现负载均衡(因为Producer是瞬态的,可以发送后关闭,无需直接等待)