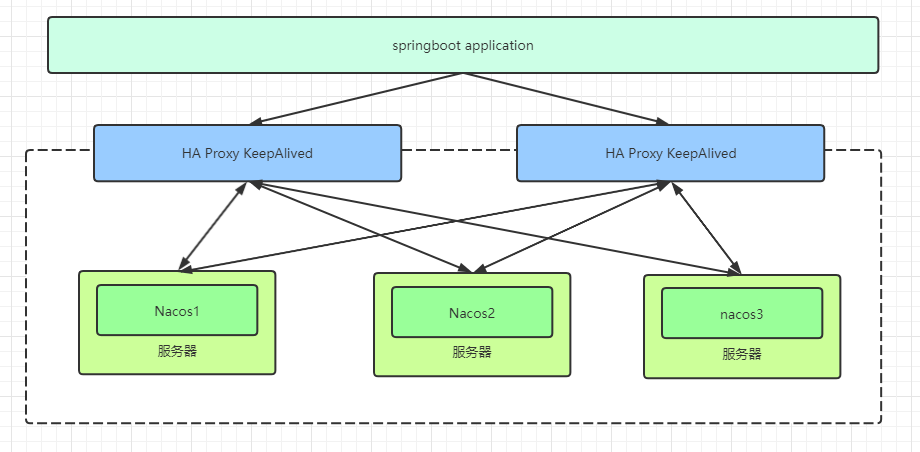
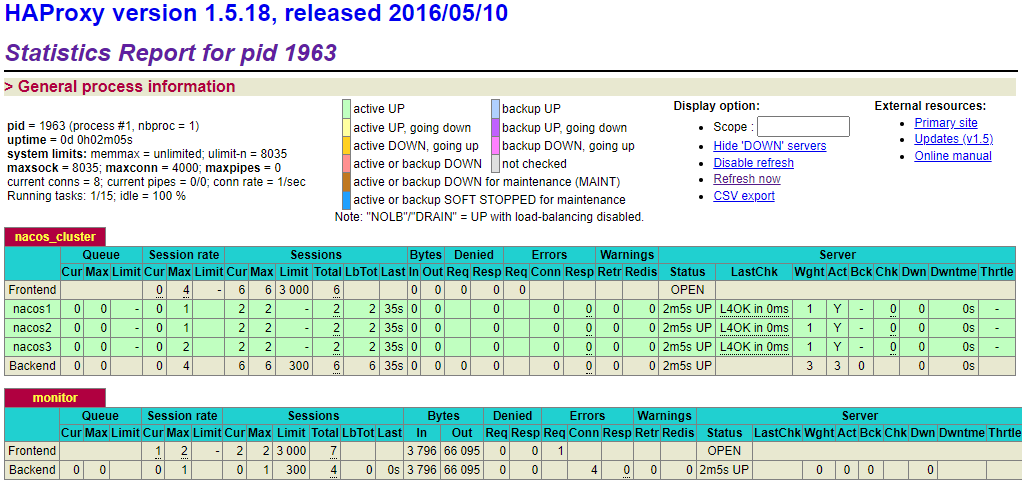
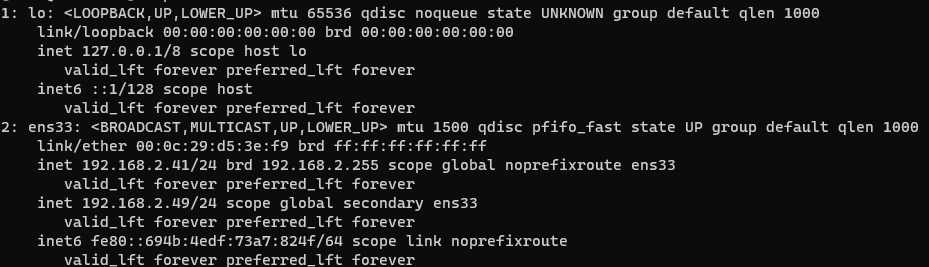
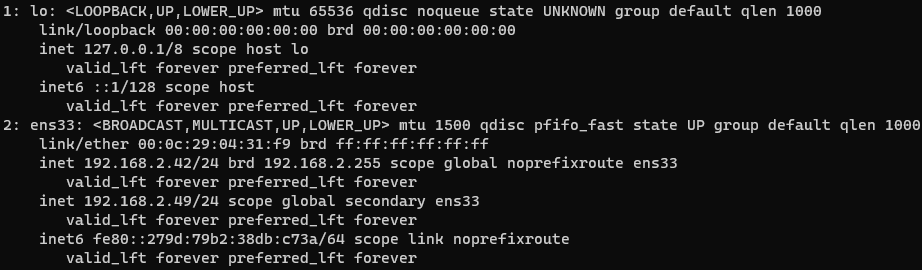
yum -y install openssl-devel gcc gcc-c++ tar -xvf keepalived-2.2.2.tar.gz cd keepalived-2.2.2 ./configure --prefix=/usr/local/keepalived make && make install mkdir /etc/keepalived
安装后的目录
1 2
yum install tree -y tree -l /usr/local/keepalived/etc
### Default web context path: server.servlet.contextPath=/nacos server.port=8848 #*************** Network Related Configurations ***************# ### If prefer hostname over ip for Nacos server addresses in cluster.conf: # nacos.inetutils.prefer-hostname-over-ip=false ### Specify local server's IP: # nacos.inetutils.ip-address= #*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://192.168.2.1:3306/nacos_db?charset=utf8mb4&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&serverTimezone=GMT%2B8&useUnicode=true&useSSL=false db.user.0=nacos db.password.0=nacos ### Connection pool configuration: hikariCP db.pool.config.connectionTimeout=30000 db.pool.config.validationTimeout=10000 db.pool.config.maximumPoolSize=20 db.pool.config.minimumIdle=2 ### will be removed and replaced by `nacos.naming.clean` properties nacos.naming.empty-service.auto-clean=true nacos.naming.empty-service.clean.initial-delay-ms=50000 nacos.naming.empty-service.clean.period-time-ms=30000 ### Since 2.1.2 ### The expired time for inactive client, unit: milliseconds. # nacos.naming.client.expired.time=180000 #*************** CMDB Module Related Configurations ***************# ### The interval to dump external CMDB in seconds: nacos.cmdb.dumpTaskInterval=3600 ### The interval of polling data change event in seconds: nacos.cmdb.eventTaskInterval=10 ### The interval of loading labels in seconds: nacos.cmdb.labelTaskInterval=300 ### If turn on data loading task: nacos.cmdb.loadDataAtStart=false # 激活Prometheus监控采集Exporter management.endpoints.web.exposure.include=* ### The auth system to use, currently only 'nacos' and 'ldap' is supported: nacos.core.auth.system.type=nacos ### If turn on auth system: nacos.core.auth.enabled=false
### Default web context path: server.servlet.contextPath=/nacos server.port=8848 #*************** Network Related Configurations ***************# ### If prefer hostname over ip for Nacos server addresses in cluster.conf: # nacos.inetutils.prefer-hostname-over-ip=false ### Specify local server's IP: # nacos.inetutils.ip-address= #*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://192.168.2.1:3306/nacos_db?charset=utf8mb4&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&serverTimezone=GMT%2B8&useUnicode=true&useSSL=false db.user.0=nacos db.password.0=nacos ### Connection pool configuration: hikariCP db.pool.config.connectionTimeout=30000 db.pool.config.validationTimeout=10000 db.pool.config.maximumPoolSize=20 db.pool.config.minimumIdle=2 #*************** Naming Module Related Configurations ***************# ### Data dispatch task execution period in milliseconds: Will removed on v2.1.X, replace with nacos.core.protocol.distro.data.sync.delayMs # nacos.naming.distro.taskDispatchPeriod=200 ### Data count of batch sync task: Will removed on v2.1.X. Deprecated # nacos.naming.distro.batchSyncKeyCount=1000 ### Retry delay in milliseconds if sync task failed: Will removed on v2.1.X, replace with nacos.core.protocol.distro.data.sync.retryDelayMs # nacos.naming.distro.syncRetryDelay=5000 ### If enable data warmup. If set to false, the server would accept request without local data preparation: # nacos.naming.data.warmup=true ### If enable the instance auto expiration, kind like of health check of instance: # nacos.naming.expireInstance=true ### will be removed and replaced by `nacos.naming.clean` properties nacos.naming.empty-service.auto-clean=true nacos.naming.empty-service.clean.initial-delay-ms=50000 nacos.naming.empty-service.clean.period-time-ms=30000 ### Add in 2.0.0 ### The interval to clean empty service, unit: milliseconds. # nacos.naming.clean.empty-service.interval=60000 ### The expired time to clean empty service, unit: milliseconds. # nacos.naming.clean.empty-service.expired-time=60000 ### The interval to clean expired metadata, unit: milliseconds. # nacos.naming.clean.expired-metadata.interval=5000 ### The expired time to clean metadata, unit: milliseconds. # nacos.naming.clean.expired-metadata.expired-time=60000 ### The delay time before push task to execute from service changed, unit: milliseconds. # nacos.naming.push.pushTaskDelay=500 ### The timeout for push task execute, unit: milliseconds. # nacos.naming.push.pushTaskTimeout=5000 ### The delay time for retrying failed push task, unit: milliseconds. # nacos.naming.push.pushTaskRetryDelay=1000 ### Since 2.1.2 ### The expired time for inactive client, unit: milliseconds. # nacos.naming.client.expired.time=180000 #*************** CMDB Module Related Configurations ***************# ### The interval to dump external CMDB in seconds: nacos.cmdb.dumpTaskInterval=3600 ### The interval of polling data change event in seconds: nacos.cmdb.eventTaskInterval=10 ### The interval of loading labels in seconds: nacos.cmdb.labelTaskInterval=300 ### If turn on data loading task: nacos.cmdb.loadDataAtStart=false #*************** Metrics Related Configurations ***************# ### Metrics for prometheus # 激活Prometheus监控采集Exporter management.endpoints.web.exposure.include=* ### Metrics for elastic search management.metrics.export.elastic.enabled=false #management.metrics.export.elastic.host=http://localhost:9200 ### Metrics for influx management.metrics.export.influx.enabled=false #management.metrics.export.influx.db=springboot #management.metrics.export.influx.uri=http://localhost:8086 #management.metrics.export.influx.auto-create-db=true #management.metrics.export.influx.consistency=one #management.metrics.export.influx.compressed=true #*************** Access Log Related Configurations ***************# ### If turn on the access log: server.tomcat.accesslog.enabled=true ### The access log pattern: server.tomcat.accesslog.pattern=%h %l %u %t "%r" %s %b %D %{User-Agent}i %{Request-Source}i ### The directory of access log: server.tomcat.basedir= #*************** Access Control Related Configurations ***************# ### If enable spring security, this option is deprecated in 1.2.0: #spring.security.enabled=false ### The ignore urls of auth, is deprecated in 1.2.0: nacos.security.ignore.urls=/,/error,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-ui/public/**,/v1/auth/**,/v1/console/health/**,/actuator/**,/v1/console/server/** ### The auth system to use, currently only 'nacos' and 'ldap' is supported: nacos.core.auth.system.type=nacos ### If turn on auth system: nacos.core.auth.enabled=true ### worked when nacos.core.auth.system.type=ldap,{0} is Placeholder,replace login username # nacos.core.auth.ldap.url=ldap://localhost:389 # nacos.core.auth.ldap.userdn=cn={0},ou=user,dc=company,dc=com ### The token expiration in seconds: nacos.core.auth.default.token.expire.seconds=18000 ### The default token: nacos.core.auth.default.token.secret.key=SecretKey012345678901234567890123456789012345678901234567890123456789 ### Turn on/off caching of auth information. By turning on this switch, the update of auth information would have a 15 seconds delay. nacos.core.auth.caching.enabled=true ### Since 1.4.1, Turn on/off white auth for user-agent: nacos-server, only for upgrade from old version. nacos.core.auth.enable.userAgentAuthWhite=false ### Since 1.4.1, worked when nacos.core.auth.enabled=true and nacos.core.auth.enable.userAgentAuthWhite=false. ### The two properties is the white list for auth and used by identity the request from other server. nacos.core.auth.server.identity.key=serverIdentity nacos.core.auth.server.identity.value=security #*************** Istio Related Configurations ***************# ### If turn on the MCP server: nacos.istio.mcp.server.enabled=false #*************** Core Related Configurations ***************# ### set the WorkerID manually # nacos.core.snowflake.worker-id= ### Member-MetaData # nacos.core.member.meta.site= # nacos.core.member.meta.adweight= # nacos.core.member.meta.weight= ### MemberLookup ### Addressing pattern category, If set, the priority is highest # nacos.core.member.lookup.type=[file,address-server] ## Set the cluster list with a configuration file or command-line argument # nacos.member.list=192.168.16.101:8847?raft_port=8807,192.168.16.101?raft_port=8808,192.168.16.101:8849?raft_port=8809 ## for AddressServerMemberLookup # Maximum number of retries to query the address server upon initialization # nacos.core.address-server.retry=5 ## Server domain name address of [address-server] mode # address.server.domain=jmenv.tbsite.net ## Server port of [address-server] mode # address.server.port=8080 ## Request address of [address-server] mode # address.server.url=/nacos/serverlist