IM的消息系统架构
前言
如今高度信息化的互联网时代,生活中Instant Messaging与我们息息相关,例如微信、钉钉等以 IM 系统为核心的产品。像一些游戏、社交软件都离不开 IM。
IM 从早起的 QQ、飞信等发展到现在,软件架构也不断的在迭代,从早期的CS、P2P演变到现在,后台已经成为了一个复杂的分布式系统,涉及网络通讯、移动端、安全、存储、检索等技术。
IM系统中最核心的是消息系统,消息系统的核心功能有消息的同步、存储和检索;
下面就基于社区比较火的 Timeline模型来构建消息系统(不依赖 TableStore)。
传统架构VS现代架构
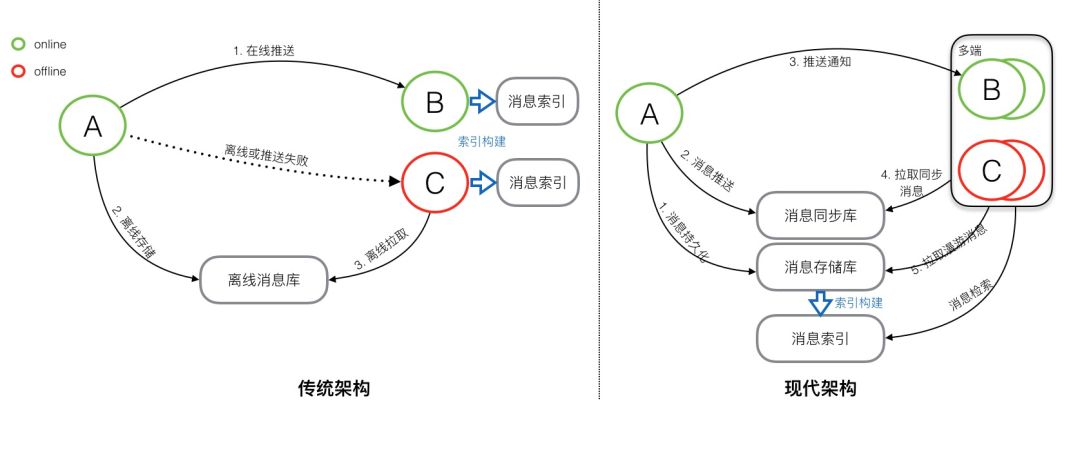
主要区别就是 现代架构下,消息是先存储后同步,消息不会丢失,多端同步、消息检索都是全量消息存储带来的好处。
现在架构下最大的挑战就是消息管理和索引。
基础模型
Timeline 模型
Timeline模型是针对消息数据场景所新创的一个数据模型,它的特色在于能够满足消息数据场景对消息保序、海量消息存储、实时同步的特殊需求。
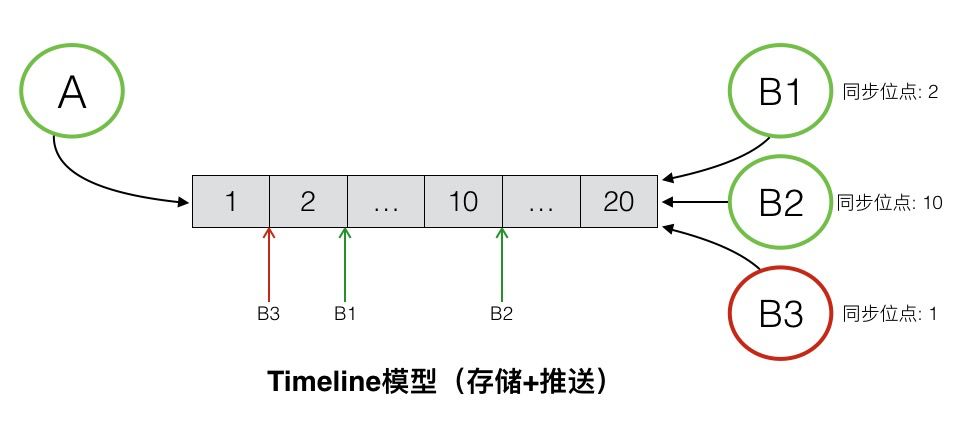
Timeline的构成主要包括:
Timeline ID:唯一标识Timeline的ID。Timeline Meta:Timeline的元数据,元数据内可包含任意键值对属性。Message Sequence:消息队列,承载该Timeline下的所有消息。消息在队列里有序保存,并且根据写入顺序分配自增的ID。一个消息队列可承载的消息个数无上限,在消息队列内部可根据消息ID随机定位某条消息,并提供正序或者反序扫描。Message Entry:消息体,包含消息的具体内容,可以包含任意键值对。
消息同步可以基于 Timeline实现,搭配 ack 机制,无障碍拉取各端消息。
消息存储可以基于 Timeline实现,持久化所有数据。
消息检索一般基于消息内容和消息类型来灵活检索。
消息存储模型
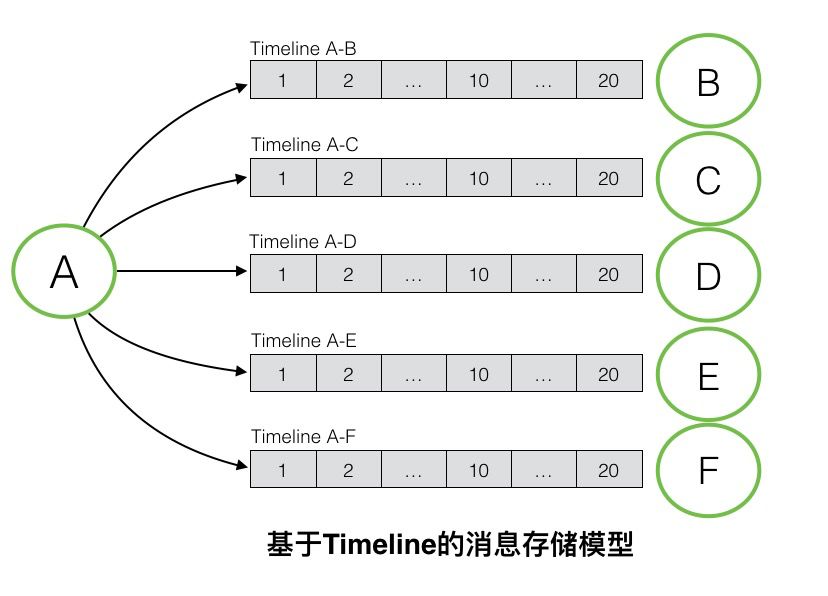
消息存储要求每个会话都对应一个 Timeline,消息根据会话顺序排序,然后持久化存储。
消息同步模型
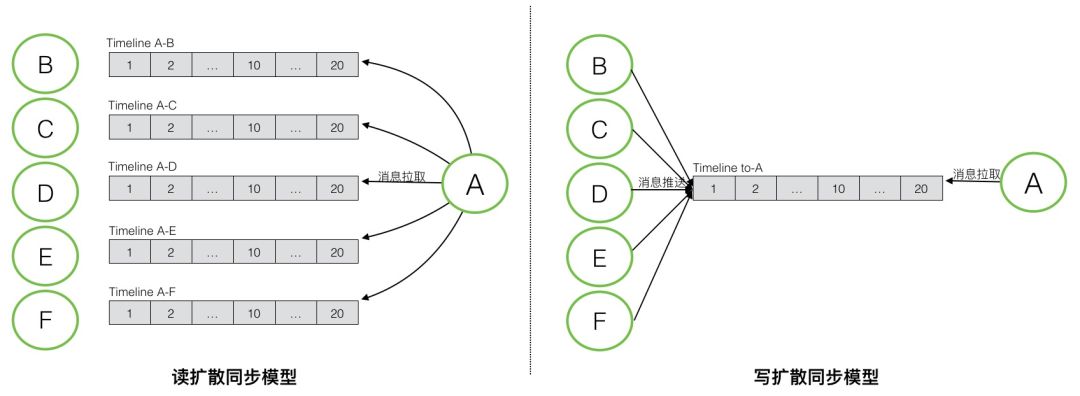
消息同步模型一般有读扩散(也叫拉模式)和写扩散(也叫推模式)两种不同的方式。
- 读扩散:消息存储模型中,每个会话的
Timeline中保存了这个会话的全量消息。读扩散的消息同步模式下,每个会话中产生的新的消息,只需要写一次到其用于存储的 Timeline 中,接收端从这个Timeline中拉取新的消息。优点是消息只需要写一次,相比写扩散的模式,能够大大降低消息写入次数,特别是在群消息这种场景下。但其缺点也比较明显,接收端去同步消息的逻辑会相对复杂和低效。接收端需要对每个会话都拉取一次才能获取全部消息,读被大大的放大,并且会产生很多无效的读,因为并不是每个会话都会有新消息产生。
- 写扩散:写扩散的消息同步模式,需要有一个额外的
Timeline来专门用于消息同步,通常是每个接收端都会拥有一个独立的同步Timeline(或者叫收件箱),用于存放需要向这个接收端同步的所有消息。每个会话中的消息,会产生多次写,除了写入用于消息存储的会话Timeline,还需要写入需要同步到的接收端的同步Timeline。在个人与个人的会话中,消息会被额外写两次,除了写入这个会话的存储Timeline,还需要写入参与这个会话的两个接收者的同步Timeline。而在群这个场景下,写入会被更加的放大,如果这个群拥有 N 个参与者,那每条消息都需要额外的写 N 次。写扩散同步模式的优点是,在接收端消息同步逻辑会非常简单,只需要从其同步Timeline中读取一次即可,大大降低了消息同步所需的读的压力。其缺点就是消息写入会被放大,特别是针对群这种场景。
Timeline 模型不会对选择读扩散还是写扩散做约束,而是能同时支持两种模式,因为本质上两种模式的逻辑数据模型并无差别,只是消息数据是用一个 Timeline 来支持多端读还是复制到多个 Timeline 来支持多端读的问题。
IM消息系统用,通常选择写扩散,消息一般写入一次,频繁读取,典型的读多写少的场景。大大增加了读的性能,用空间换时间。但是对于万人大群,读扩散又是一个好的选择。
架构设计
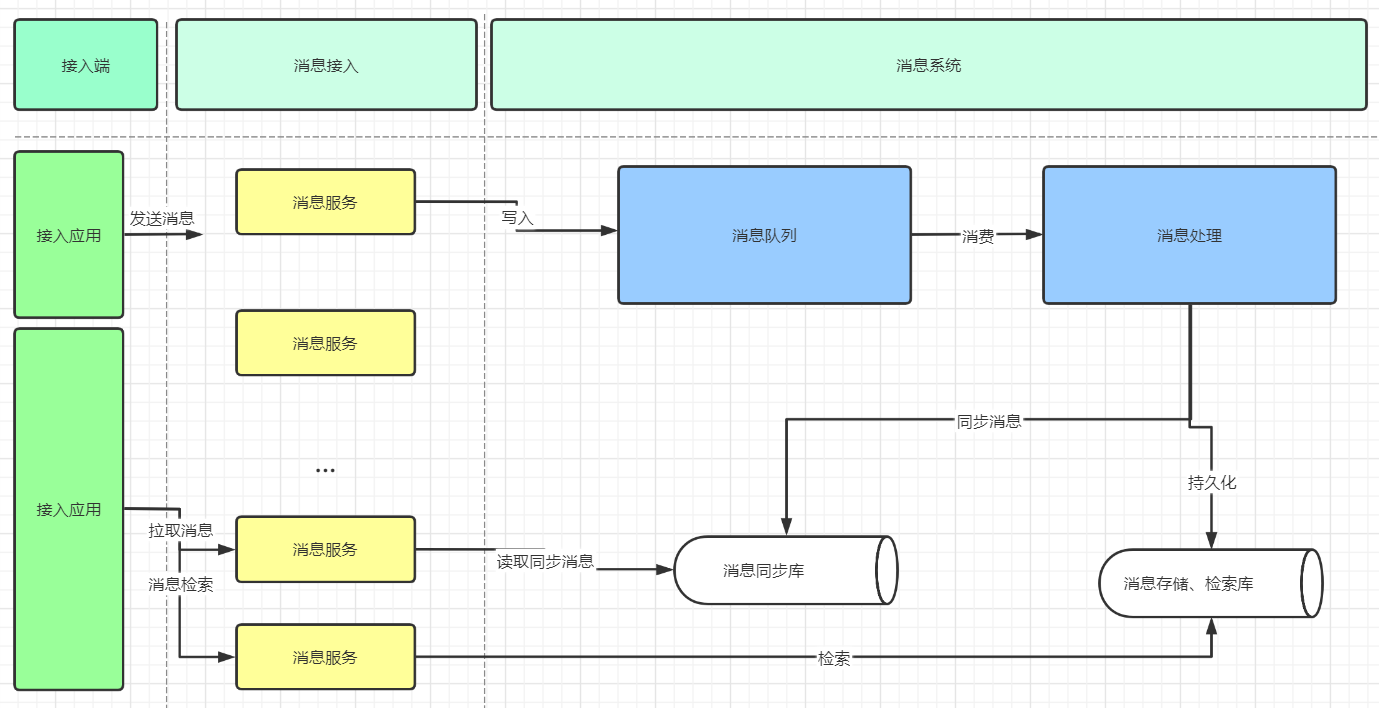
如图是一个典型的消息系统架构,架构中包含几个重要组件:
- 接入端:作为消息的发送和接收端。
- 消息服务:一组无状态的服务器,可水平扩展,处理消息的发送和接收请求,连接后端消息系统。
- 消息队列:新写入消息的缓冲队列,消息系统的前置消息存储,用于削峰填谷以及异步消费。
- 消息处理:一组无状态的消费处理服务器,用于异步消费消息队列中的消息数据,处理消息的持久化和写扩散同步。
- 消息存储和索引库:持久化存储消息,每个会话对应一个
Timeline进行消息存储,存储的消息建立索引来实现消息检索。 - 消息同步库:写扩散形式同步消息,每个用户的收件箱对应一个 Timeline,同步库内消息不需要永久保存,通常对消息设定一个生命周期。
新消息会由端发出,通常消息体中会携带消息 ID(用于去重)、逻辑时间戳(用于排序)、消息类型(控制消息、图片消息或者文本消息等)、消息体等内容。消息会先写入消息队列,作为底层存储的一个临时缓冲区。消息队列中的消息会由消息处理服务器消费,可以允许乱序消费。消息处理服务器对消息先存储后同步,先写入发件箱 Timeline(存储库),后写扩散至各个接收端的收件箱(同步库)。消息数据写入存储库后,会被近实时的构建索引,索引包括文本消息的全文索引以及多字段索引(发送方、消息类型等)。
对于在线的设备,可以由消息服务器主动推送至在线设备端。对于离线设备,登录后会主动向服务端同步消息。每个设备会在本地保留有最新一条消息的顺序 ID,向服务端同步该顺序 ID 后的所有消息。
数据库选型
基于 TableStore
消息系统最核心的两个库是消息同步库和消息存储库,两个库对数据库有不同的要求:
| 消息同步库 | 消息存储库 | |
|---|---|---|
| 数据模型 | Timeline模型 | Timeline模型 |
| 写能力 | 高并发写,十万级TPS | 高并发写,少量读,万级TPS |
| 读能力 | 高并发范围读,十万级TPS | 少量范围读,千级TPS |
| 存储规模 | 保存一段时间内的同步消息,TB级。保留千万级的Timeline规模。 |
保存全量消息,百TB级。保留亿级的Timeline规模。 |
总结下来,对数据库的要求有如下几点:
- 表结构设计能够满足
Timeline模型的功能要求:不要求关系模型,能够实现队列模型,并能够支持生成自增的SeqId。 - 能够支持高并发写和范围读,规模在十万级TPS。
- 能够保存海量数据,百TB级。
- 能够为数据定义生命周期。
阿里云表格存储(TableStore)是基于LSM存储引擎的分布式NoSQL数据库,支持百万TPS高并发读写,PB级数据存储,数据支持TTL,能够很好的满足以上需求,并且支持自增列,能够非常完美的设计和实现Timeline的物理模型。
基于传统数据库
| 消息同步库 | 消息存储库 | |
|---|---|---|
| 数据模型 | MongoDB | MySQL |
| 写能力 | 高并发写,万级TPS | 高并发写,少量读,千级TPS |
| 读能力 | 高并发范围读,万级TPS | 少量范围读,千级TPS |
| 存储规模 | 保存一段时间内的同步消息,GB级。 | 保存全量消息,GB级。 |
在写能力与读能力上,基于目前所用服务器的性能标准,在目标上与TableStore存储有巨大差距。